
使用AIAK-Inference 加速推理业务
前提条件
- 选择CCR中的AIAK-Inference推理加速镜像作为基础镜像。
- 运行环境需提供 GPU,并可使用
docker或等效容器运行时启动目标镜像。## 操作流程
Tensorflow模型优化
在CCR公共镜像的“百度智能云AI镜像”中选择aiak-inference:ubuntu18.04-cu11.2-tf2.4.1-py3.6-aiak1.1-latest这个tag(或使用docker pull registry.baidubce.com/ai-public/aiak-inference:ubuntu18.04-cu11.2-tf2.4.1-py3.6-aiak1.1-latest拉取镜像),镜像内部已经安装好了CUDA、Tensorflow 2.4.1等基础库。
在容器内准备示例模型:
1import os
2import tarfile
3import urllib.request
4
5import numpy as np
6import tensorflow.compat.v1 as tf
7
8tf.disable_eager_execution()
9
10MODEL_URL = 'http://url/to/your/model/YOUR_MODEL.tar.gz'
11
12
13def _prepare_demo_model():
14 local_tgz = os.path.basename(MODEL_URL)
15 local_dir = local_tgz.split('.')[0]
16 if not os.path.exists(local_dir):
17 urllib.request.urlretrieve(MODEL_URL, local_tgz)
18 with tarfile.open(local_tgz) as archive:
19 archive.extractall(local_dir)
20
21 model_path = os.path.abspath(os.path.join(local_dir, 'frozen_inference_graph.pb'))
22 graph_def = tf.GraphDef()
23 with tf.gfile.GFile(model_path, 'rb') as file_obj:
24 graph_def.ParseFromString(file_obj.read())
25
26 test_data = np.random.rand(1, 800, 1000, 3).astype(np.float32)
27 return graph_def, {'image_tensor:0': test_data}
28
29
30graph_def, test_data = _prepare_demo_model()
31
32input_nodes = ['image_tensor']
33output_nodes = [
34 'detection_boxes',
35 'detection_scores',
36 'detection_classes',
37 'num_detections',
38 'detection_masks',
39]
40fetches = [f'{name}:0' for name in output_nodes]请将 MODEL_URL 替换为可访问的模型压缩包地址,并确保解压后包含 frozen_inference_graph.pb 文件。示例中的 fetches 由 output_nodes 补齐 :0 后缀,用于在 benchmark 阶段直接取回输出结果。
然后尝试推理这个模型:
1import time
2
3
4def benchmark(model):
5 tf.reset_default_graph()
6 with tf.Session() as sess:
7 tf.import_graph_def(model, name='')
8
9 for _ in range(1000):
10 sess.run(fetches, feed_dict=test_data)
11
12 num_runs = 1000
13 start = time.time()
14 for _ in range(num_runs):
15 sess.run(fetches, feed_dict=test_data)
16
17 elapsed = time.time() - start
18 rt_ms = elapsed / num_runs * 1000.0
19 print('Latency of model: {:.2f} ms.'.format(rt_ms))
20
21
22print('before compile:')
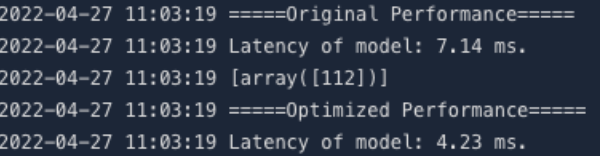
23benchmark(graph_def)benchmark(...) 输出的 Latency of model 表示单次推理的平均时延,单位为 ms。
接下来引入AIAK-Inference优化:
1import aiak_inference
2optimized_model = aiak_inference.optimize(
3graph_def,
4'gpu',
5outputs=['detection_boxes', 'detection_scores', 'detection_classes', 'num_detections', 'detection_masks']
6) aiak_inference.optimize(...) 的参数说明如下:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
graph_def |
tf.GraphDef |
是 | 待优化的 TensorFlow 静态图。 |
'gpu' |
str |
是 | 指定优化目标为 GPU。 |
outputs |
list[str] |
是 | 模型输出节点名称列表,不带 :0 后缀。 |
返回值说明:optimized_model 为优化后的 GraphDef,可继续复用同一组 feed_dict 与 benchmark 逻辑进行推理。优化后的模型仍然是一个GraphDef模型,可以使用同样的代码进行推理:
1# optimized graph
2print("after compile:")
3benchmark(optimized_model)对比优化前后的 benchmark 结果,可观察模型性能变化:
PyTorch模型优化
在CCR公共镜像的“AI加速镜像”中选择aiak-inference:cuda11.2_cudnn8_trt8.4_torch1.11-aiak_1.1.1_latest加速镜像(或使用docker pull registry.baidubce.com/ai-public/aiak-inference:cuda11.2_cudnn8_trt8.4_torch1.11-aiak_1.1.1_latest拉取镜像),镜像内部已经安装好了CUDA、PyTorch 1.11等基础库。
在容器中准备PyTorch相关模型,以ResNet50为例:
1import os
2import time
3import torch
4import torchvision.models as models
5
6model = models.resnet50().float().cuda()
7model = torch.jit.script(model).eval() # 使用jit转为静态图
8dummy = torch.rand(1, 3, 224, 224).cuda()尝试进行推理:
1@torch.no_grad()
2def benchmark(model, inp):
3 for i in range(100):
4 model(inp)
5 start = time.time()
6 for i in range(200):
7 model(inp)
8 elapsed_ms = (time.time() - start) * 1000
9 print("Latency: {:.2f}".format(elapsed_ms / 200))
10
11# benchmark before optimization
12print("before optimization:")
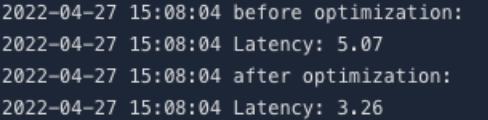
13benchmark(model, dummy)benchmark(...) 输出的 Latency 表示单次推理的平均时延,单位为 ms。接着使用AIAK-Inference进行模型优化,并得到优化后的模型:
1import aiak_inference
2
3optimized_model = aiak_inference.optimize(
4model,
5'gpu',
6test_data=[dummy],
7)aiak_inference.optimize(...) 的参数说明如下:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
model |
torch.jit.ScriptModule |
是 | 待优化的 PyTorch 静态图模型。 |
'gpu' |
str |
是 | 指定优化目标为 GPU。 |
test_data |
list[torch.Tensor] |
是 | 用于生成优化配置的示例输入,示例中为 [dummy]。 |
返回值说明:optimized_model 为优化后的可调用模型,输入签名与原模型保持一致,可直接复用原有 benchmark 调用方式。再次进行推理:
1# benchmark after optimization
2print("after optimization:")
3benchmark(optimized_model, dummy)比较二者性能,可观察单次推理延迟下降:
评价此篇文章