
GPU独占和共享说明
若集群支持 GPU 算力和显存的共享与隔离,您可以在新建任务或工作负载的时候,根据提交的 YAML 来决定独占还是共享 GPU 资源。
前提条件
- 您已成功安装CCE GPU Manager 和 CCE AI Job Scheduler 组件。您可在“集群>组件管理>云原生AI”中安装。
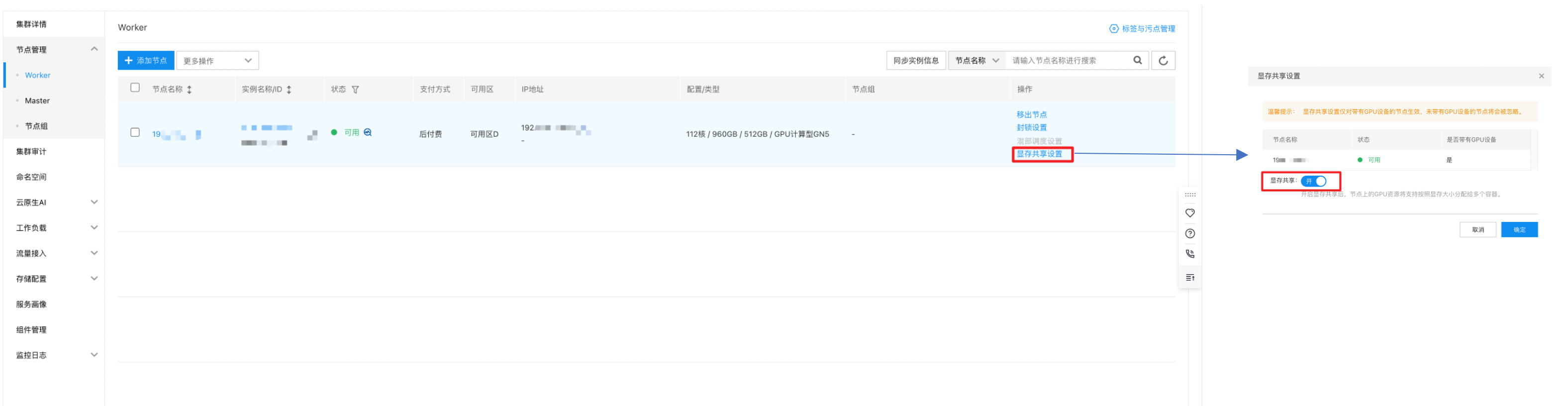
- 节点已开启显存共享,您可在“集群>节点管理>Worker>显存共享配置”中开启。
GPU卡型号对应资源名称
为保证正常使用GPU资源,请正确指定GPU卡型号对应的资源名称,本文以使用GPU卡数量为例,若想指定GPU卡算力资源或显存资源,则在资源名称后加上“_core”或“_memory”即可。
| GPU卡型号 | 资源名称 |
|---|---|
| NVIDIA A800-SXM4-80GB | baidu.com/a800_80g_cgpu |
| NVIDIA A100-SXM4-80GB | baidu.com/a100_80g_cgpu |
| NVIDIA A100-SXM4-40GB | baidu.com/a100_40g_cgpu |
| NVIDIA A10 | baidu.com/a10_24g_cgpu |
| NVIDIA A30 | baidu.com/a30_24g_cgpu |
| Tesla V100-SXM2-32GB | baidu.com/v100_32g_cgpu |
| Tesla V100-SXM2-16GB | baidu.com/v100_16g_cgpu |
| Tesla T4 | baidu.com/t4_16g_cgpu |
| NVIDIA GeForce RTX 3090 | baidu.com/rtx_3090_cgpu |
| NVIDIA GeForce RTX 3080 | baidu.com/rtx_3080_cgpu |
| NVIDIA GeForce RTX 4090 | baidu.com/rtx_4090_cgpu |
| NVIDIA H800 | baidu.com/h800_80g_cgpu |
| NVIDIA GPU | nvidia.com/gpu |
| L20 | baidu.com/l20_cgpu |
| NVIDIA H20 | baidu.com/h20_96g_cgpu |
| NVIDIA H20-3e | baidu.com/h20_141g_cgpu |
| NVIDIA H20Z | baidu.com/h20z_141g_cgpu |
| Huawei Ascend910 | huawei.com/Ascend910 |
| KUNLUNXIN-R480 | baidu.com/xpu |
| KUNLUNXIN-P800 | kunlunxin.com/xpu |
资源描述
| 资源名称 | 类型 | 单位 | 说明 |
|---|---|---|---|
| baidu.com/v100_32g_cgpu_core | int64 | 5% | GPU 卡算力,eg.100=单卡总算力,10=单卡算力的10%,要求最低5% |
| baidu.com/v100_32g_cgpu_memory | int64 | GiB | GPU 卡显存 |
| baidu.com/v100_32g_cgpu_memory_percent | int64 | 1% | 按百分比申请 GPU 卡显存,eg.100=单卡总显存 ,10=单卡显存的10% |
Yaml创建任务/工作负载示例
若您通过Yaml创建任务或工作负载(详细配置可参考云原生AI任务管理、工作负载),您可在Yaml配置中指定所需GPU卡资源为独占或共享,具体示例如下:
备注:
1、如使用Yaml的方式创建任务,调度器必须指定schedulerName: volcano
2、GPU显存资源必须申请,且baidu.com/v100_32g_cgpu_memory和baidu.com/v100_32g_cgpu_memory_percent只能填写一个,不可同时填写
1. 关闭 CCE GPU Manager组件 精细化调度
单卡独占示例:
1resources:
2 requests:
3 baidu.com/cgpu: 1 // 1卡
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/cgpu: 1 // limit与request必须一致
8 cpu: "4"
9 memory: 60Gi多卡独占示例:
1resources:
2 requests:
3 baidu.com/cgpu: 2 // 2卡
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/cgpu: 2 // limit与request必须一致
8 cpu: "4"
9 memory: 60Gi单卡共享【不进行算力隔离,只有显存隔离】示例:
1resources:
2 requests:
3 baidu.com/cgpu_memory: 10 // 10GB,用户可根据自己的需求填写
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/cgpu_memory: 10
8 cpu: "4"
9 memory: 60Gi单卡共享【同时支持显存隔离和算力隔离】示例:
1resources:
2 requests:
3 baidu.com/cgpu_core: 50 // 50%, 0.5卡算力,用户可根据自己的需求填写
4 baidu.com/cgpu_memory: 10 // 10GB,用户可根据自己的需求填写
5 cpu: "4"
6 memory: 60Gi
7 limits:
8 baidu.com/cgpu_core: 50
9 baidu.com/cgpu_memory: 10
10 cpu: "4"
11 memory: 60Gi单容器多卡能力【GPU显存/算力同时隔离&仅显存隔离】示例:
通过指定资源描述符使用cGPU的单容器多卡能力,分为GPU显存/算力同时隔离以及仅隔离显存的场景。
-
GPU显存/算力同时隔离
单张共享卡的资源:
- 每张 GPU卡的算力资源:baidu.com/cgpu、baidu.com/cgpu_core/
- 每张 GPU卡的显存资源:baidu.com/cgpu_memory
资源描述示例,如下示例代表:该Pod共申请50%的算力,以及10GiB的显存,2张GPU共享卡。所以每张GPU共享卡的资源为 25%的算力以及5GiB显存。
1resources:
2 limits:
3 baidu.com/cgpu: "2"
4 baidu.com/cgpu_core: "50"
5 baidu.com/cgpu_memory: "10"-
GPU显存隔离,算力共享
单张共享卡的资源:
- 每张 GPU卡的算力资源:baidu.com/cgpu,与其他容器共享100%的算力。
- 每张 GPU卡的显存资源:baidu.com/cgpu_memory
资源描述示例,如下示例代表:该Pod共申请10GiB的显存,2张GPU共享卡。所以每张GPU共享卡的资源为 共享100%的算力以及5GiB显存。
1 resources:
2 limits:
3 baidu.com/cgpu: "2"
4 baidu.com/cgpu_memory: "10"- 使用限制
- 单卡的显存/算力需要为正整数, 即算力(baidu.com/cgpu、baidu.com/cgpu_core),显存(baidu.com/cgpu_memory )需为正整数。
- 单卡的显存/算力需要大于等于显存/算力的最小单位。
- 如果没有申请_cgpu_memory或者_cgpu_memory_percent,是不允许申请_cgpu_core
- 显存隔离最小单位:1GiB,算力的最小单位是单卡的5%。
2. 开启 CCE GPU Manager组件 精细化调度
该示例为CCE GPU Manager组件,精细化调度开启状态下的YAML配置文件(创建队列和任务时均支持选择具体的GPU型号)。
单卡独占示例:
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 1 // 1卡
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu: 1 // limit与request必须一致
8 cpu: "4"
9 memory: 60Gi多卡独占示例:
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 2 // 2卡
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu: 2 // limit与request必须一致
8 cpu: "4"
9 memory: 60Gi单卡共享【不进行算力隔离,只有显存隔离】示例:
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu_memory: 10 // 10GB,用户可根据自己的需求填写
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu_memory: 10
8 cpu: "4"
9 memory: 60Gi单卡共享【同时支持显存隔离和算力隔离】示例:
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu_core: 50 // 50%, 0.5卡算力,用户可根据自己的需求填写
4 baidu.com/v100_32g_cgpu_memory: 10 // 10GB,用户可根据自己的需求填写
5 cpu: "4"
6 memory: 60Gi
7 limits:
8 baidu.com/v100_32g_cgpu_core: 50 //
9 baidu.com/v100_32g_cgpu_memory: 10
10 cpu: "4"
11 memory: 60Gi单容器多卡能力【GPU显存/算力同时隔离&仅显存隔离】示例:
通过指定资源描述符使用cGPU的单容器多卡能力,分为GPU显存/算力同时隔离以及仅隔离显存的场景。
-
GPU显存/算力同时隔离
单张共享卡的资源:
- 每张 GPU卡的算力资源:baidu.com/xxx_xxx_cgpu、baidu.com/xxx_xxx_cgpu_core
- 每张 GPU卡的显存资源:baidu.com/xxx_xxx_cgpu_memory
资源描述示例,如下示例代表:该Pod共申请50%的算力,以及10GiB的显存,2张GPU共享卡。所以每张GPU共享卡的资源为 25%的算力以及5GiB显存。
1resources:
2 limits:
3 baidu.com/a10_24g_cgpu: "2"
4 baidu.com/a10_24g_cgpu_core: "50"
5 baidu.com/a10_24g_cgpu_memory: "10"-
GPU显存隔离,算力共享
单张共享卡的资源:
- 每张 GPU卡的算力资源:baidu.com/xxx_xxx_cgpu,与其他容器共享100%的算力。
- 每张 GPU卡的显存资源:baidu.com/xxx_xxx_cgpu_memory
资源描述示例,如下示例代表:该Pod共申请10GiB的显存,2张GPU共享卡。所以每张GPU共享卡的资源为 共享100%的算力以及5GiB显存。
1 resources:
2 limits:
3 baidu.com/a10_24g_cgpu: "2"
4 baidu.com/a10_24g_cgpu_memory: "10"- 使用限制
- 单卡的显存/算力需要为正整数, 即算力(baidu.com/xxx_xxx_cgpu、baidu.com/xxx_xxx_cgpu_core),显存(baidu.com/xxx_xxx_cgpu_memory )需为正整数。
- 单卡的显存/算力需要大于等于显存/算力的最小单位。
- 如果没有申请_cgpu_memory或者_cgpu_memory_percent,是不允许申请_cgpu_core
- 显存隔离最小单位:1GiB,算力的最小单位是单卡的5%。
3. CPU调度Yaml示例
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: nginx-deployment
5spec:
6 selector:
7 matchLabels:
8 app: nginx
9 replicas: 1
10 template:
11 metadata:
12 labels:
13 app: nginx
14 spec:
15 containers:
16 - name: nginx
17 image: registry.baidubce.com/public/nginx:latest
18 ports:
19 - containerPort: 80
20 resources: # 资源限制
21 limits:
22 cpu: 250m
23 memory: 512Mi
24 requests:
25 cpu: 250m
26 memory: 512Mi4. BCI调度Yaml示例
将一个副本部署到BCI的yaml示例:
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 labels:
5 app: nginx-test
6 name: nginx-test
7 namespace: default
8spec:
9 replicas: 1
10 selector:
11 matchLabels:
12 app: nginx-test
13 template:
14 metadata:
15 labels:
16 app: nginx-test
17 name: nginx-test
18 spec:
19 containers:
20 - command:
21 - /bin/sh
22 - -c
23 - sleep 36000
24 image: registry.baidubce.com/my-bci-public/nginx-test-500m:20240528
25 imagePullPolicy: Always
26 name: nginx-test
27 resources:
28 limits:
29 cpu: 250m
30 memory: 512Mi
31 nodeSelector:
32 type: virtual-kubelet
33 restartPolicy: Always
34 tolerations:
35 - effect: NoSchedule
36 key: virtual-kubelet.io/provider
37 operator: Equal
38 value: baidu更多相关信息,请参见CCE虚拟节点管理文档、BCI Pod配置文档、BCI管理运维文档。