视图命令行场景示例
更新时间:2023-11-20
一般的问题定位流程可以分为五个阶段:问题发现 => 数据导出 => 关键错误提取 => 视图分析 => 问题处理
场景1:资源超配额
- 问题发现:pytorchjob 没有进入running状态,对应的pod长时间pending
Plain Text
1% kubectl get pytorchjob
2NAME STATE AGE
3pytorchjob-bert-2-bert Created 58m
4
5% kubectl get pod
6pytorchjob-bert-2-bert-master-0 0/2 Pending 0 58m
7pytorchjob-bert-2-bert-worker-0 0/2 Pending 0 58m- 调整日志级别,获取视图文件与日志文件
Plain Text
1# 调整日志等级到4
2% cce-volcano-cli log -v 4
34
4# dump日志与视图文件
5cce-volcano-cli dump -l 5000
6copy file volcano-scheduler-7848fb7487-44fpq:/dump/volcano.1695461246.snapshot to ./volcano.1695461246.snapshot success!
7start dump volcano logfile volcano.1695461246.log
8end dump volcano logfile volcano.1695461246.log
9
10# 调整日志等级到3
11% cce-volcano-cli log -v 3 -k kubeconfig
123- 关键错误提取:通过job日志,发现ExceedQueueResource,因此需要对队列配额分配情况进行分析
Plain Text
1% cce-volcano-cli log job -f volcano.1695461246.log -j pytorchjob-bert-2-bert 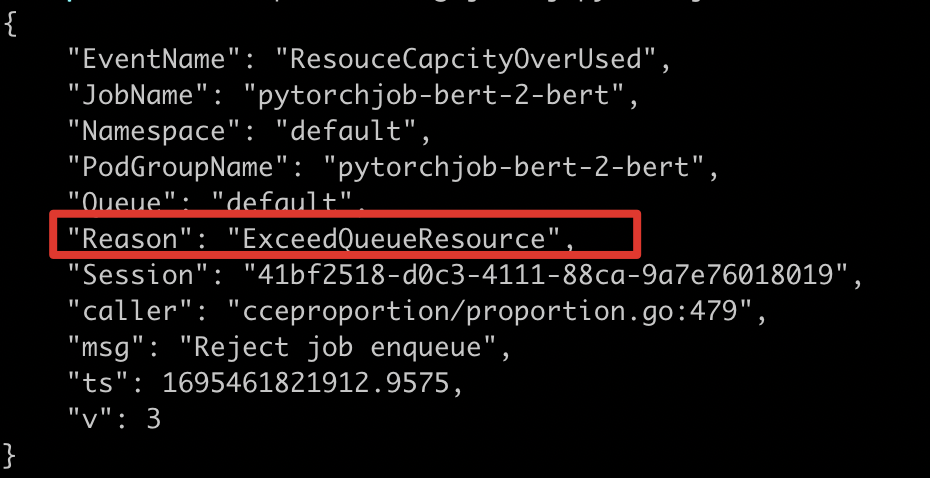
得到配额不足的错误信息以后,可以使用 cce-volcano-cli queue 命令对队列配额进行分析,常见的几种情况如下
case1 队列配额不足
a800资源已经用完,其中总卡数为8,已分配5卡,排队中4卡
Plain Text
1% cce-volcano-cli queue -f volcano.1695461246.snapshot
case2 混合卡调度
对于混合申请的场景,工具提供了totalGPU字段,用于统计实际剩余的卡数,可以看到总卡数为8,已分配5卡,排队中4卡,剩余卡为-1。
已分配的卡中,1个通过baidu.com/a800_80g_cgpu的方式申请,4个通过nvidia.com/gpu的方式申请。排队中的4卡使用了baidu.com/a800_80g_cgpu的方式申请
Plain Text
1% cce-volcano-cli queue -f volcano.1695461246.snapshot
case3 podgroup残留
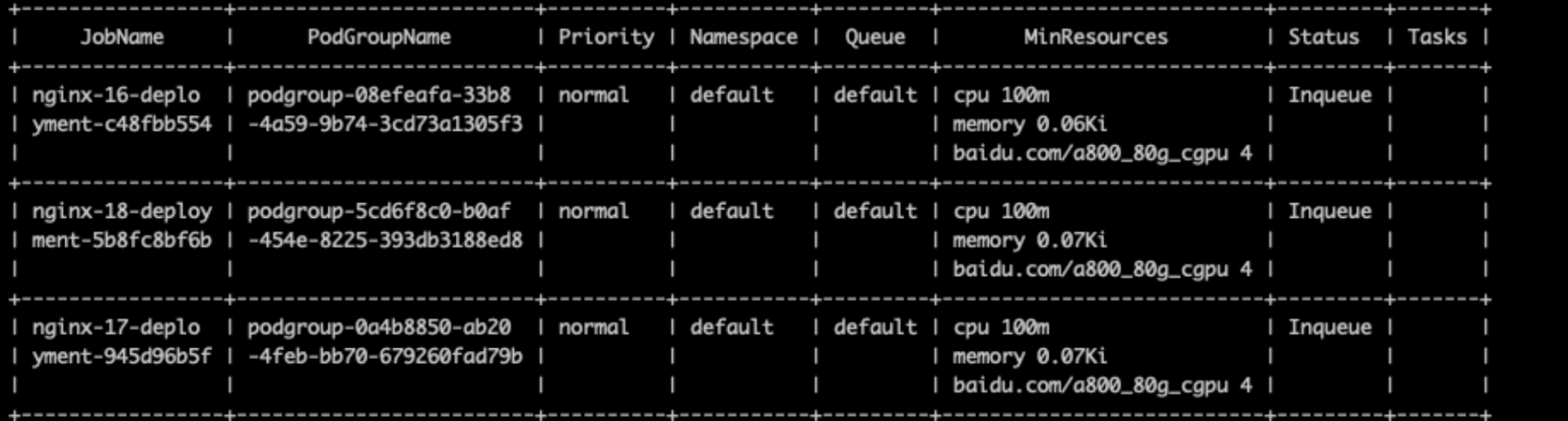
inqueue状态资源较多,实际还剩3卡没有用起来
Plain Text
1% cce-volcano-cli queue -f volcano.1695461246.snapshot
Plain Text
1使用cce-volcano-cli job命令进行job视图分析,查看inqueue状态job列表,并对其中的异常job做清理
2% cce-volcano-cli job -f volcano.1695461246.snapshot -a
3工具提供了-t选项对这种异常的job列表进行筛选
4% cce-volcano-cli job -f volcano.1695461246.snapshot -t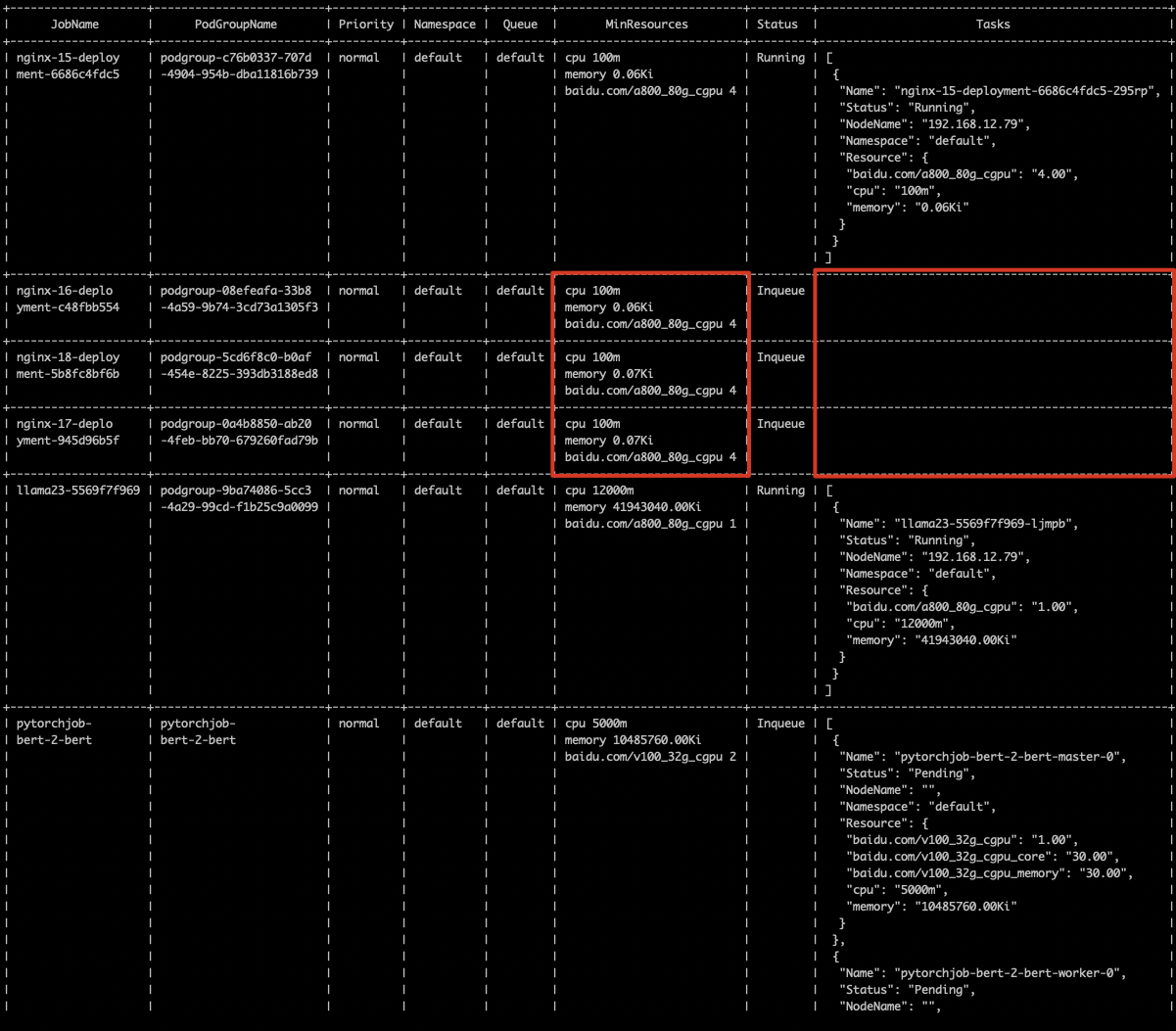
场景2 亲和性、污点、GPU资源不足
- 问题发现:job一直是Created状态,pod pending
Plain Text
1% kubectl get PyTorchJob
2NAME STATE AGE
3pytorchjob-bert Created 36s
4% kubectl get pod
5NAME READY STATUS RESTARTS AGE
6pytorchjob-bert-master-0 0/2 Pending 0 39s- 关键错误提取:通过job日志,发现GangUnschedulable,不满足gang调度,由此可以知道是pod调度失败导致pending,继续查pod失败原因
Plain Text
1# 收集CCE AI Job Scheduler日志
2% cce-volcano-cli dump -l 5000
3# 通过命令行查看job级别日志./c
4% cce-volcano-cli log job -f volcano.1698844162.log -j pytorchjob-bert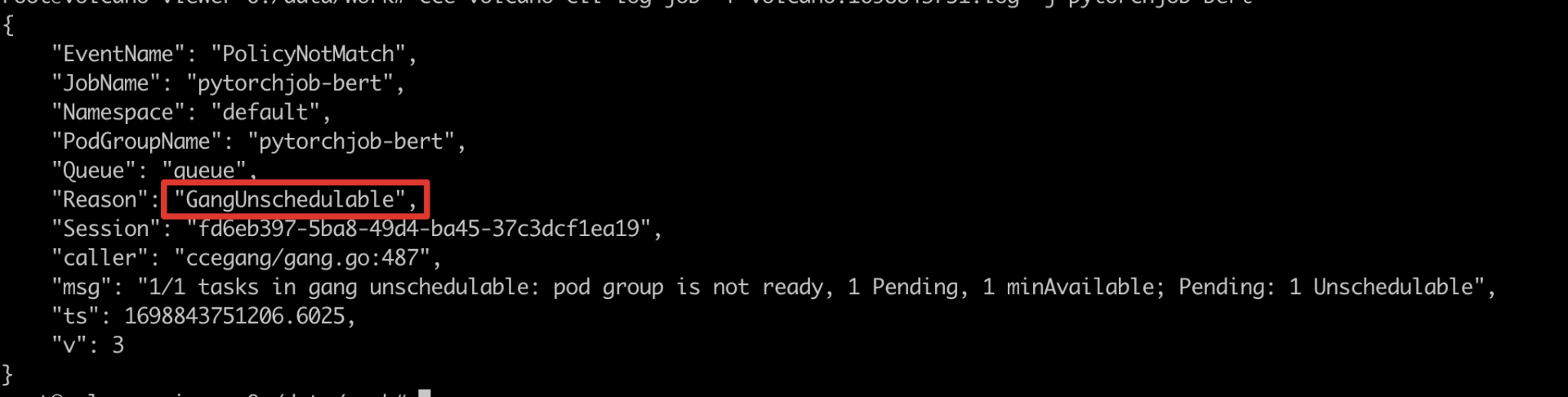
- 通过命令行查看pod级别日志
Plain Text
1# 通过命令行查看pod级别日志
2% cce-volcano-cli log pod -f volcano.1698844162.log -p pytorchjob-bert-master-0
192.168.14.5 是封锁节点
192.168.11.181 cpu或者memory资源不足
192.168.14.142 10.0.3 10.0.4 节点有污点
case 1 亲和性匹配
通过node视图分析:10.0.0.181 cpu资源不足(job申请1000m cpu,node剩余50m)。
10.0.0.3 10.0.0.4 10.0.0.142 节点有gpu资源但是有污点,无法调度,需要确认是否使用该节点。
10.0.0.5 是封锁节点(status:Unschedulable)。
Plain Text
1% cce-volcano-cli node -f volcano.1698844162.snapshot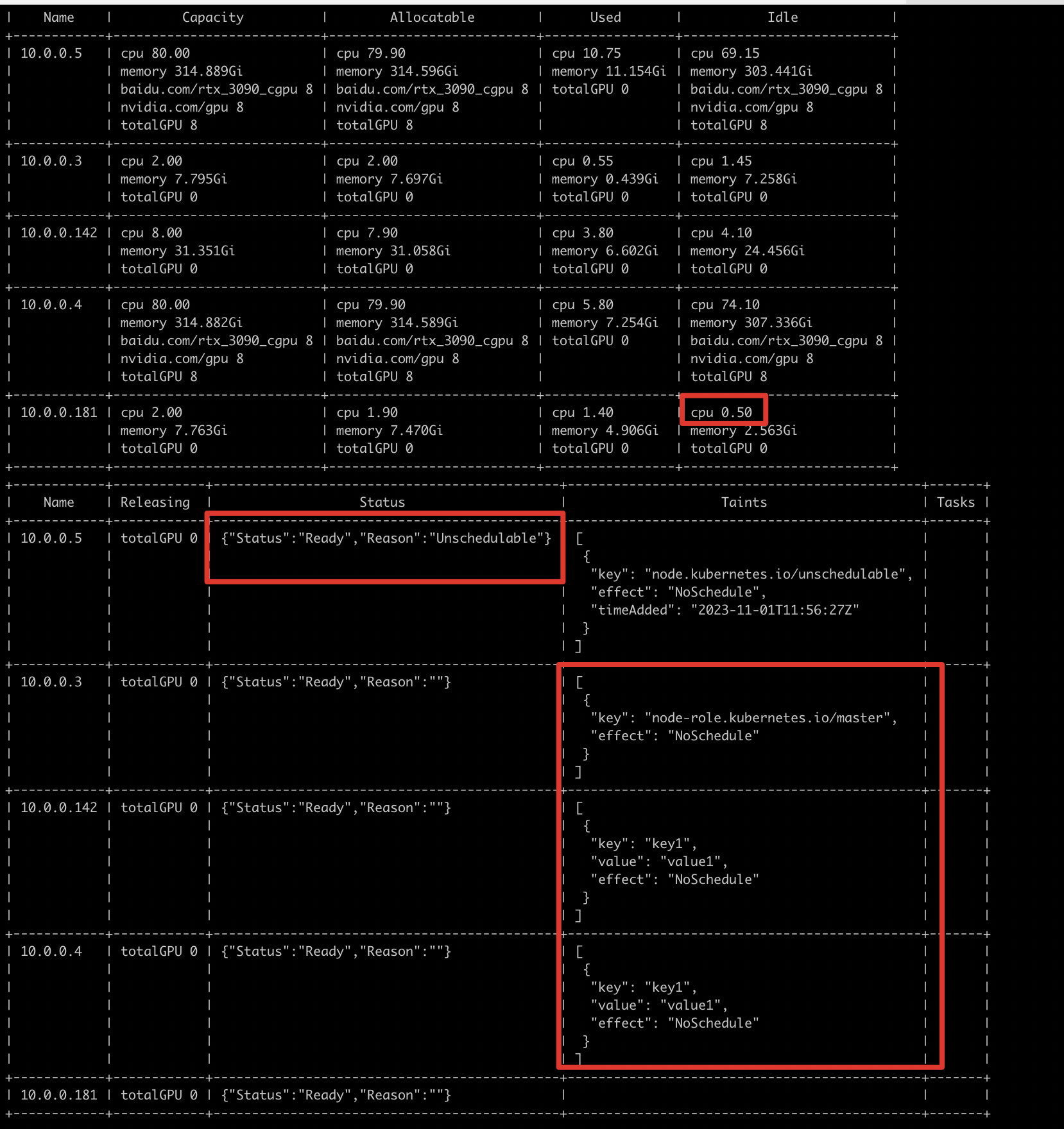
case 2 gpu掉卡
如果节点有gpu资源,并且任务需要卡数<=node节点卡数,仍然无法调度。可查看node视图,判断是否掉卡。
如下图所示,发现节点的allocatable的nvidia.com/gpu<节点capacity ,初步判断节点掉卡。
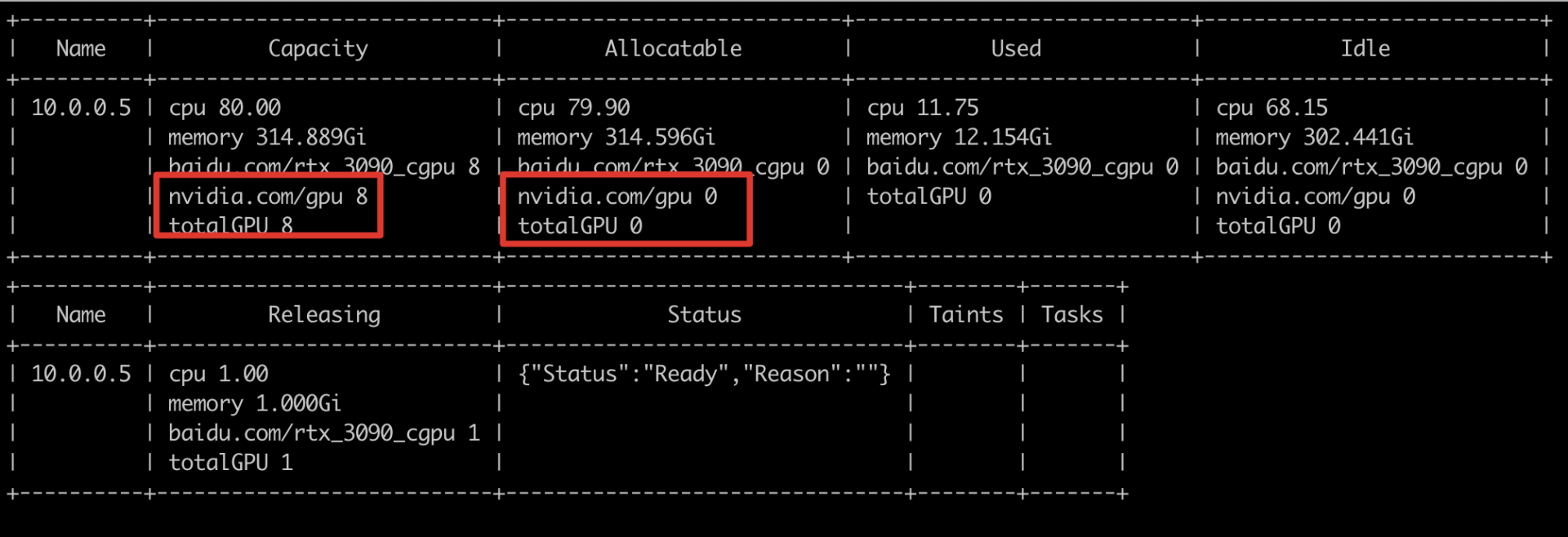
describe node发现,nvidia.com/gpu为0,确认掉卡。