
端到端语音语言大模型API
接口描述
百度端到端语音语言大模型基于业内首创的Cross-Attention跨模态语音大模型,具备极速响应、拟人音色,实现真人级别语音对话交互。极致共情、超高双商,支持深度需求理解与复杂任务执行。广泛应用于实时语音交互的情感陪伴、社交娱乐以及知识问答等场景。请点击链接进入端到端语音大模型详情。
产品优势
超低时延:基于业内创新的Cross-Attention技术,在对话过程中将用户等待时长从行业常见的3-5秒大幅缩短至1秒左右,实现了比拟真人对话的即时响应速度,树立行业标杆。 极致共情:基于真正的端到端跨模态语音大模型,能够感知原始语音携带的情绪与语气信息,充分理解用户意图与情境要求,更好地服务情感陪伴、 社交娱乐等场景。 超拟人音色:合成前端融入大语言模型,成就高自然度、高表现力的语音合成系统,使合成音频听感更加自然流畅,语气更加符合情境,情感更加接近真人,语调更加具有韵律。
接口调用详情
交互流程
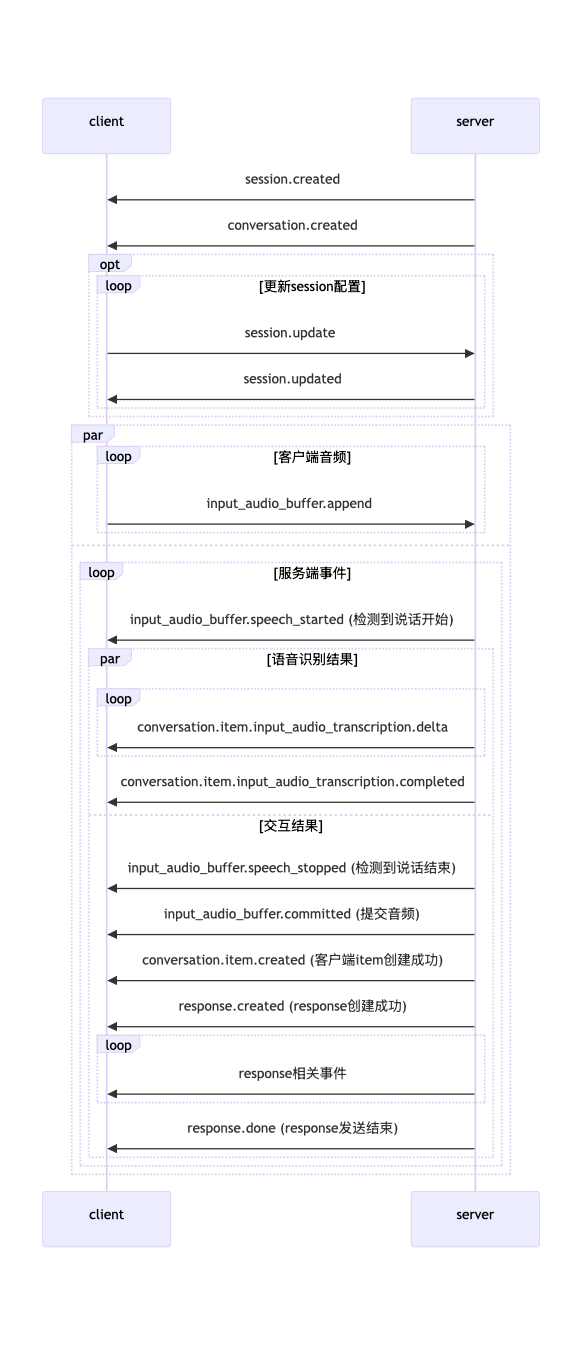
response事件交互
接口说明
请求地址
请求地址:wss://aip.baidubce.com/ws/2.0/speech/v1/realtime
认证鉴权
支持 API Key 和 access_token 两种方式,具体请参考鉴权认证机制。
请求参数
URL中放置请求参数,参数如下:
| 参数名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| model | string | 必填 | 模型名称 |
示例:wss://aip.baidubce.com/ws/2.0/speech/v1/realtime?model=audio-realtime-far
附:
| 模型 | 模型名称 | 适用场景 |
|---|---|---|
| 端到端语音语言大模型(Lite) | audio-mini-realtime-near | 高性能、近场场景 |
| 端到端语音语言大模型(Lite) | audio-mini-realtime-far | 高性能、远场场景 |
| 端到端语音语言大模型(Pro) | audio-realtime-near | 高优效果、近场场景 |
| 端到端语音语言大模型(Pro) | audio-realtime-far | 高优效果、远场场景 |
客户端事件
session.update
事件描述
客户端session.update事件用于更新会话的默认配置,服务端以session.updated包含完整有效配置的事件进行响应
事件参数
| 参数名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| type | string | 必填 | 事件类型,必须是session.update |
| event_id | string | 可选 | 事件唯一标识 |
| session | UpdateSession | 必填 | 会话配置 |
示例
1{
2 "type": "session.update",
3 "session": {
4 "input_audio_transcription": {
5 "model": "default"
6 }
7 }
8}input_audio_buffer.append
事件描述
客户端input_audio_buffer.append事件用于将音频字节附加到输入音频缓冲区
事件参数
| 参数名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| type | string | 必填 | 事件类型,必须是input_audio_buffer.append |
| event_id | string | 可选 | 事件唯一标识 |
| audio | string | 必填 | Base64 编码的音频字节,固定单声道、16000采样率 |
示例
1{
2 "type": "input_audio_buffer.append",
3 "audio": "audio_base64"
4}服务端事件
session.created
事件描述
服务端session.created事件是建立新连接时的第一个服务器事件,此事件会使用默认会话配置创建并返回一个新会话
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是session.created |
| event_id | string | 事件唯一标识 |
| session | Session | 会话配置 |
示例
1{
2 "type": "session.created",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_Hjr7Au95",
4 "session": {
5 "id": "sess_ywqGIVMsrQKh8jY4WhYZ",
6 "object": "realtime.session",
7 "expires_at": 1752218581,
8 "input_audio_format": "pcm16",
9 "input_audio_noise_reduction": null,
10 "input_audio_transcription": null,
11 "instructions": "",
12 "max_response_output_tokens": "inf",
13 "modalities": [
14 "text",
15 "audio"
16 ],
17 "model": "audio-realtime",
18 "output_audio_format": "pcm16",
19 "speed": 1,
20 "temperature": 0.8,
21 "tool_choice": "auto",
22 "tools": [],
23 "tracing": null,
24 "turn_detection": {
25 "type": "server_vad",
26 "threshold": 0.5,
27 "prefix_padding_ms": 300,
28 "silence_duration_ms": 200,
29 "create_response": true,
30 "interrupt_response": true
31 },
32 "voice": "default"
33 }
34}session.updated
事件描述
服务端session.updated对客户端用于更新会话默认配置的session.update事件进行响应,响应事件包含完整有效配置
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是session.updated |
| event_id | string | 事件唯一标识 |
| session | Session | 会话配置 |
示例
1{
2 "type": "session.updated",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_hSIhy0aC",
4 "session": {
5 "id": "sess_ywqGIVMsrQKh8jY4WhYZ",
6 "object": "realtime.session",
7 "expires_at": 1752218581,
8 "input_audio_format": "pcm16",
9 "input_audio_noise_reduction": null,
10 "input_audio_transcription": {
11 "model": "default",
12 "language": null,
13 "prompt": null
14 },
15 "instructions": "",
16 "max_response_output_tokens": "inf",
17 "modalities": [
18 "text",
19 "audio"
20 ],
21 "model": "audio-realtime",
22 "output_audio_format": "pcm16",
23 "speed": 1,
24 "temperature": 0.8,
25 "tool_choice": "auto",
26 "tools": [],
27 "tracing": null,
28 "turn_detection": {
29 "type": "server_vad",
30 "threshold": 0.5,
31 "prefix_padding_ms": 300,
32 "silence_duration_ms": 200,
33 "create_response": true,
34 "interrupt_response": true
35 },
36 "voice": "default"
37 }
38}conversation.created
事件描述
会话创建后,立即返回服务端conversation.created事件
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是conversation.created |
| event_id | string | 事件唯一标识 |
| conversation | Conversation | 会话资源 |
示例
1{
2 "type": "conversation.created",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_bt89NXfx",
4 "conversation": {
5 "id": "conv_auVpdUi6cvWu5ANDjL25",
6 "object": "realtime.conversation"
7 }
8}conversation.item.created
事件描述
客户端发过来的音频已加入到对话中时,返回conversation.item.created服务端事件
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是conversation.item.created |
| event_id | string | 事件唯一标识 |
| previous_item_id | string | 在对话中此项目之前的项目的 ID,创建的首个项目该值为null |
| item | ConversationItem | 创建的消息 |
示例
1{
2 "type": "conversation.item.created",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_CklwHSkg",
4 "previous_item_id": null,
5 "item": {
6 "id": "item_ywqGIVMsrQKh8jY4WhYZ_001",
7 "object": "realtime.item",
8 "type": "message",
9 "status": "completed",
10 "role": "user",
11 "content": [{
12 "type": "input_audio",
13 "transcript": "今天天气怎么样?"
14 }]
15 }
16}conversation.item.input_audio_transcription.delta
事件描述
输入音频对应的ASR识别结果
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是conversation.item.input_audio_transcription.delta |
| event_id | string | 事件唯一标识 |
| item_id | string | 用户消息项目的 ID |
| content_index | integer | 默认0 |
| delta | string | 识别文本 |
示例
1{
2 "type": "conversation.item.input_audio_transcription.delta",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_8o0XL7DD",
4 "item_id": "item_ywqGIVMsrQKh8jY4WhYZ_001",
5 "content_index": 0,
6 "delta": "今"
7}conversation.item.input_audio_transcription.completed
事件描述
服务端conversation.item.input_audio_transcription.completed事件是将语音的音频转录写入音频缓冲区的结果
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是conversation.item.input_audio_transcription.completed |
| event_id | string | 事件唯一标识 |
| item_id | string | 包含音频的用户消息项目的 ID |
| content_index | integer | 包含音频的内容部分的索引 |
| transcript | string | 转录出的文本 |
示例
1{
2 "type": "conversation.item.input_audio_transcription.completed",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_sCk3x7cv",
4 "item_id": "item_ywqGIVMsrQKh8jY4WhYZ_001",
5 "content_index": 0,
6 "transcript": "今天天气怎么样?"
7}conversation.item.input_audio_transcription.failed
事件描述
当配置了输入音频转录,并且用户消息的转录请求失败时,会返回服务器conversation.item.input_audio_transcription.failed事件。此事件与其他事件分开,error以便客户端可以识别相关项目
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是conversation.item.input_audio_transcription.failed |
| event_id | string | 事件唯一标识 |
| item_id | string | 用户消息项目的ID |
| content_index | integer | 包含音频的内容部分的索 |
| error | Error | 转录错误的详细信息。 |
示例
1{
2 "type": "conversation.item.input_audio_transcription.failed",
3 "event_id": "event_Ula21nRHDN0DDc4GT280_3f38VTVO",
4 "item_id": "item_Ula21nRHDN0DDc4GT280_001",
5 "content_index": 0,
6 "error": {
7 "type": "server_error",
8 "code": "internal",
9 "message": "error message"
10 }
11}input_audio_buffer.committed
事件描述
当输入音频缓冲区提交时,返回服务端事件input_audio_buffer.committed
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须为input_audio_buffer.committed |
| event_id | string | 事件唯一标识 |
| previous_item_id | string | 在对话中此项目之前的项目的 ID,创建的首个项目该值为null |
| item_id | string | 创建消息项目的ID |
示例
1{
2 "type": "input_audio_buffer.committed",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_kyvsH2Ur",
4 "previous_item_id": null,
5 "item_id": "item_ywqGIVMsrQKh8jY4WhYZ_001"
6}input_audio_buffer.speech_started
事件描述
当在音频缓冲区中检测到语音时,在server_vad模式下返回服务端input_audio_buffer.speech_started事件
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型必须是input_audio_buffer.speech_started |
| event_id | string | 事件唯一标识 |
| item_id | string | 服务端检测到客户端会话时,语音停止时会创建的用户消息项的ID |
示例
1{
2 "type": "input_audio_buffer.speech_started",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_W3Zas9hP",
4 "item_id": "item_ywqGIVMsrQKh8jY4WhYZ_001"
5}input_audio_buffer.speech_stopped
事件描述
当服务端检测到音频缓冲区中的语音结束时,返回input_audio_buffer.speech_stopped服务端事件
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是input_audio_buffer.speech_stopped |
| event_id | string | 事件唯一标识 |
| item_id | string | 用户消息项目的 ID |
示例
1{
2 "type": "input_audio_buffer.speech_stopped",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_s0ROBCxD",
4 "item_id": "item_ywqGIVMsrQKh8jY4WhYZ_001"
5}response.created
事件描述
当初次响应被创建时,会返回服务端response.created事件。这是响应创建的第一个事件,响应的初始状态为in_progress
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.created |
| event_id | string | 事件唯一标识 |
| response | Response | 响应对象 |
示例
1{
2 "type": "response.created",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_nclqvTp",
4 "response": {
5 "id": "resp_ywqGIVMsrQKh8jY4WhYZ_001",
6 "object": "realtime.response",
7 "status": "in_progress",
8 "status_details": {
9 "type": "in_progress"
10 },
11 "output": [],
12 "conversation_id": "conv_auVpdUi6cvWu5ANDjL25",
13 "modalities": [
14 "text",
15 "audio"
16 ],
17 "voice": "default",
18 "output_audio_format": "pcm16",
19 "temperature": 0.8,
20 "max_output_tokens": "inf"
21 }
22}response.done
事件描述
当响应流式传输完成后,无论最终状态如何,会返回服务器事件response.done,事件中包含的响应对象包含响应中的所有输出项,但会省略原始音频数据
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.done |
| response | Response | 响应对象 |
示例
1{
2 "type": "response.done",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_07u3tDT3",
4 "response": {
5 "id": "resp_ywqGIVMsrQKh8jY4WhYZ_001",
6 "object": "realtime.response",
7 "status": "cancelled",
8 "status_details": {
9 "type": "cancelled",
10 "reason": "turn_detected"
11 },
12 "output": [{
13 "id": "item_ywqGIVMsrQKh8jY4WhYZ_002",
14 "object": "realtime.item",
15 "type": "message",
16 "status": "incomplete",
17 "role": "assistant",
18 "content": [{
19 "type": "audio",
20 "transcript": "今天的天气呀,我其实不太清楚呢,因为这得看具体的地方呀。你可以告诉我你在哪里,或者你自己看看窗外的天气怎么样呀,对不对?"
21 }]
22 }],
23 "conversation_id": "conv_auVpdUi6cvWu5ANDjL25",
24 "modalities": [
25 "text",
26 "audio"
27 ],
28 "voice": "default",
29 "output_audio_format": "pcm16",
30 "temperature": 0.8,
31 "max_output_tokens": "inf"
32 }
33}response.output_item.added
事件描述
response.output_item.added在响应生成期间创建新项目消息
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.output_item.added |
| event_id | string | 事件唯一标识 |
| response_id | string | 该项目所属的响应的 ID |
| output_index | integer | 响应中输出项的索引 |
| item | ConversationItem | 已添加的项目 |
示例
1{
2 "type": "response.output_item.added",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_yvrV5UAs",
4 "response_id": "resp_ywqGIVMsrQKh8jY4WhYZ_001",
5 "output_index": 0,
6 "item": {
7 "id": "item_ywqGIVMsrQKh8jY4WhYZ_002",
8 "object": "realtime.item",
9 "type": "message",
10 "status": "in_progress",
11 "role": "assistant",
12 "content": []
13 }
14}response.output_item.done
事件描述
当项目流式传输完成时或响应被中断、不完整或取消时,将返回此服务器事件response.output_item.done
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.output_item.added |
| event_id | string | 事件唯一标识 |
| response_id | string | 该项目所属的响应的 ID |
| output_index | integer | 响应中输出项的索引 |
| item | ConversationItem | 已添加的项目 |
示例
1{
2 "type": "response.output_item.done",
3 "event_id": "event_ywqGIVMsrQKh8jY4WhYZ_TDVWUShW",
4 "response_id": "resp_ywqGIVMsrQKh8jY4WhYZ_001",
5 "output_index": 0,
6 "item": {
7 "id": "item_ywqGIVMsrQKh8jY4WhYZ_002",
8 "object": "realtime.item",
9 "type": "message",
10 "status": "incomplete",
11 "role": "assistant",
12 "content": [{
13 "type": "audio",
14 "transcript": "今天的天气呀,我其实不太清楚呢,因为这得看具体的地方呀。你可以告诉我你在哪里,或者你自己看看窗外的天气怎么样呀,对不对?"
15 }]
16 }
17}response.content_part.added
事件描述
在响应生成期间将新的内容部分添加到助手消息项时,将返回服务器事件response.content_part.added
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.content_part.added |
| event_id | string | 事件唯一标识 |
| response_id | string | 响应的 ID |
| item_id | string | 添加了内容部分的消息项目的 ID |
| output_index | integer | 响应中输出项的索引 |
| content_index | integer | 项目内容数组中内容部分的索引 |
| part | ConversationItemContent | 新增的内容部分 |
示例
1 {
2 "type": "response.content_part.added",
3 "event_id": "event_Ula21nRHDN0DDc4GT280_wa1BMTuP",
4 "response_id": "resp_Ula21nRHDN0DDc4GT280_001",
5 "item_id": "item_Ula21nRHDN0DDc4GT280_002",
6 "output_index": 0,
7 "content_index": 0,
8 "part": {
9 "type": "audio",
10 "transcript": ""
11 }
12}response.content_part.done
事件描述
在响应生成期间将内容部分添加到助手消息项完成时,将返回服务器事件response.content_part.done
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.content_part.done |
| event_id | string | 事件唯一标识 |
| response_id | string | 响应的 ID |
| item_id | string | 添加了内容部分的消息项目的 ID |
| output_index | integer | 响应中输出项的索引 |
| content_index | integer | 项目内容数组中内容部分的索引 |
| part | ConversationItemContent | 内容部分 |
示例
1{
2 "type": "response.content_part.done",
3 "event_id": "event_Ula21nRHDN0DDc4GT280_L6W3WslV",
4 "response_id": "resp_Ula21nRHDN0DDc4GT280_001",
5 "item_id": "item_Ula21nRHDN0DDc4GT280_002",
6 "output_index": 0,
7 "content_index": 0,
8 "part": {
9 "type": "audio",
10 "transcript": "当然会呀!一闪一闪亮晶晶,满天都是小星星,挂在天上放光明,好像许多小眼睛!要不要我再唱一段给你听呀?"
11 }
12}response.audio.delta
事件描述
在响应生成期间音频内容发生变化时,将返回服务器事件response.audio.delta
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.audio.delta |
| event_id | string | 事件唯一标识 |
| response_id | string | 响应的 ID |
| item_id | string | 添加了内容部分的消息项目的 ID |
| output_index | integer | 响应中输出项的索引 |
| content_index | integer | 项目内容数组中内容部分的索引 |
| delta | string | 音频内容的base64编码 |
示例
1 {
2 "type": "response.audio.delta",
3 "event_id": "event_Ula21nRHDN0DDc4GT280_yZemLoGb",
4 "response_id": "resp_Ula21nRHDN0DDc4GT280_001",
5 "item_id": "item_Ula21nRHDN0DDc4GT280_002",
6 "output_index": 0,
7 "content_index": 0,
8 "delta": "audio_base64"
9}response.audio.done
事件描述
在响应生成期间音频内容完成时,将返回服务器事件response.audio.done
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.audio.done |
| event_id | string | 事件唯一标识 |
| response_id | string | 响应的 ID |
| item_id | string | 添加了内容部分的消息项目的 ID |
| output_index | integer | 响应中输出项的索引 |
| content_index | integer | 项目内容数组中内容部分的索引 |
示例
1{
2 "type": "response.audio.done",
3 "event_id": "event_Ula21nRHDN0DDc4GT280_WLL6zFxV",
4 "response_id": "resp_Ula21nRHDN0DDc4GT280_001",
5 "item_id": "item_Ula21nRHDN0DDc4GT280_002",
6 "output_index": 0,
7 "content_index": 0
8}response.audio_transcript.delta
事件描述
当模型输出新的音频转录文本时,将返回服务端事件response.audio_transcript.delta
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.audio_transcript.delta |
| event_id | string | 事件唯一标识 |
| response_id | string | 响应的 ID |
| item_id | string | 添加了内容部分的消息项目的 ID |
| output_index | integer | 响应中输出项的索引 |
| content_index | integer | 项目内容数组中内容部分的索引 |
| delta | string | 当轮对话音频已转录的文本 |
示例
1 {
2 "type": "response.audio_transcript.delta",
3 "event_id": "event_Ula21nRHDN0DDc4GT280_4iuzQnqh",
4 "response_id": "resp_Ula21nRHDN0DDc4GT280_001",
5 "item_id": "item_Ula21nRHDN0DDc4GT280_002",
6 "output_index": 0,
7 "content_index": 0,
8 "delta": "当然会呀"
9}response.audio_transcript.done
事件描述
当模型生成的音频转录输出完成时,服务端将返回response.audio_transcript.done事件
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 事件类型,必须是response.audio_transcript.done |
| event_id | string | 事件唯一标识 |
| response_id | string | 响应的 ID |
| item_id | string | 添加了内容部分的消息项目的 ID |
| output_index | integer | 响应中输出项的索引 |
| content_index | integer | 项目内容数组中内容部分的索引 |
| transcript | string | 转录文本 |
示例
1{
2 "type": "response.audio_transcript.done",
3 "event_id": "event_Ula21nRHDN0DDc4GT280_eS2AxK1L",
4 "response_id": "resp_Ula21nRHDN0DDc4GT280_001",
5 "item_id": "item_Ula21nRHDN0DDc4GT280_002",
6 "output_index": 0,
7 "content_index": 0,
8 "transcript": "当然会呀!一闪一闪亮晶晶,满天都是小星星,挂在天上放光明,好像许多小眼睛!要不要我再唱一段给你听呀?"
9}数据类型
Session
类型描述
该session数据类型代表API中的会话
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| id | string | 会话的唯一 ID |
| object | string | 固定值realtime.response |
| expires_at | integer | 会话过期的时间戳,以秒为单位 |
| input_audio_format | string | 输入音频的格式,默认pcm16 |
| input_audio_noise_reduction | InputAudioNoiseReduction | 输入音频降噪配置,null表示不开启 |
| input_audio_transcription | InputAudioTranscription | 输入音频转录配置,null表示不开启 |
| instructions | string | 系统指令,不超过2500个字符。最佳实践请参考附录,当前只有Pro版本支持该功能 |
| max_response_output_tokens | integer / string | 模型生成输出的最大token数,默认"inf" |
| modalities | string [] | 输出模态,仅支持["text", "audio"] |
| model | string | 模型名称 |
| output_audio_format | string | 目前仅支持pcm16 |
| speed | float | 语速,取值0.5-1.5,默认为1中语速 |
| temperature | float | 模型的采样温度 |
| turn_detection | TurnDetection | 轮次检测VAD配置,null表示关闭VAD |
| voice | string | 度沁雪=8003(默认音色),度小舒=8014,度灵静=8008,度海棠=8021 |
示例
1{
2 "id": "sess_ywqGIVMsrQKh8jY4WhYZ",
3 "object": "realtime.session",
4 "expires_at": 1752218581,
5 "input_audio_format": "pcm16",
6 "input_audio_noise_reduction": null,
7 "input_audio_transcription": {
8 "model": "default",
9 "language": null,
10 "prompt": null
11 },
12 "instructions": "",
13 "max_response_output_tokens": "inf",
14 "modalities": [
15 "text",
16 "audio"
17 ],
18 "model": "audio-realtime",
19 "output_audio_format": "pcm16",
20 "speed": 1,
21 "temperature": 0.8,
22 "tool_choice": "auto",
23 "tools": [],
24 "tracing": null,
25 "turn_detection": {
26 "type": "server_vad",
27 "threshold": 0.5,
28 "prefix_padding_ms": 300,
29 "silence_duration_ms": 200,
30 "create_response": true,
31 "interrupt_response": true
32 },
33 "voice": "default"
34}UpdateSession
类型描述
如果想通过session.update事件更新会话配置时,可以使用该对象
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| input_audio_format | string | 输入音频的格式,默认pcm16 |
| input_audio_transcription | InputAudioTranscription | 输入音频转录配置,null表示不开启 |
| instructions | string | 系统指令,不超过2500个字符 |
| max_response_output_tokens | integer / string | 模型生成输出的最大token数,"inf"或者1~1500范围内的整数 |
| output_audio_format | string | 目前仅支持pcm16 |
| speed | float | 语速,取值0.5-1.5,默认为1中语速 |
| turn_detection | TurnDetection | 轮次检测VAD配置,null表示关闭VAD |
| voice | string | 模型用于响应的语音 |
示例
1{
2 "input_audio_format": "pcm16",
3 "input_audio_transcription": {
4 "model": "default",
5 },
6 "output_audio_format": "pcm16",
7 "speed": 1,
8 "turn_detection": {
9 "type": "server_vad",
10 "create_response": true,
11 "interrupt_response": true
12 },
13 "voice": "default"
14}InputAudioNoiseReduction
类型描述
输入音频降噪配置。
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 降噪类型,支持near_field、far_field |
InputAudioTranscription
类型描述
输入音频转录配置。
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| model | string | 转录模型,该配置为必填项,支持的值:default |
| language | string | 输入音频的语言,支持值:zh |
| prompt | string | 音频转录的提示词,暂不支持 |
TurnDetection
类型描述
轮次检测VAD配置。
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 检测类型,目前仅支持server_vad |
| create_response | boolean | 是否在检测到静音后自动生成响应,目前仅支持true |
| interrupt_response | boolean | 是否允许在播放语音响应过程中被打断,目前仅支持true |
Conversation
类型描述
表示一个对话对象
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| id | string | 对话唯一ID |
| object | string | 固定值realtime.conversation |
示例
1{
2 "id": "conv_auVpdUi6cvWu5ANDjL25",
3 "object": "realtime.conversation"
4}ConversationItem
类型描述
代表对话中的一个项目
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| id | string | 唯一ID |
| object | string | 固定值realtime.item |
| type | string | 类型。允许的值:message |
| status | string | 当前内容状态,"in_progress" 表示生成中,"completed" 表示已完成,"incompleted" 表示不完整 |
| role | string | 发言者角色,user、assistant、system |
| content | ConversationItemContent[] | 项目内容 |
示例
1{
2 "id": "item_ywqGIVMsrQKh8jY4WhYZ_002",
3 "object": "realtime.item",
4 "type": "message",
5 "status": "incomplete",
6 "role": "assistant",
7 "content": [{
8 "type": "audio",
9 "transcript": "今天的天气呀,我其实不太清楚呢,因为这得看具体的地方呀。你可以告诉我你在哪里,或者你自己看看窗外的天气怎么样呀,对不对?"
10 }]
11}ConversationItemContent
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 内容类型。枚举值有:input_text、input_audio、item_reference、text、audio |
| text | string | 文本内容,用于 input_text 和 text 内容类型 |
| audio | string | Base64 编码的音频字节,用于 input_audio 和 audio 内容类型 |
| transcripts | string | 音频的转录,用于"input_audio" 和"audio" 内容类型 |
示例
1{
2 "type": "audio",
3 "transcript": "今天的天气呀,我其实不太清楚呢,因为这得看具体的地方呀。你可以告诉我你在哪里,或者你自己看看窗外的天气怎么样呀,对不对?"
4}Response
类型描述
Response代表服务端返回的响应类型
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| id | string | 响应的唯一ID |
| object | string | 固定为realtime.response |
| status | string | 响应的状态:in_progress、completed、cancelled、incomplete、failed |
| status_details | ResponseStatusDetails | 响应状态的详细信息 |
| output | ConversationItem[] | 响应的输出项目 |
| conversation_id | string | 响应对应的对话id |
| modalities | string[] | 模型可以响应的模态集合:["text", "audio"] |
| voice | string | 输出语音模型 |
| output_audio_format | string | 目前仅支持pcm16 |
| temperature | float | 模型的采样温度 |
| max_output_tokens | string / integer | 此响应使用的最大输出令牌数,包括工具调用 |
示例
1{
2 "id": "resp_0mYKGHLhTPGZ4BoeM7Bs_031",
3 "object": "realtime.response",
4 "status": "completed",
5 "status_details": {
6 "type": "completed"
7 },
8 "output": [
9 {
10 "id": "item_0mYKGHLhTPGZ4BoeM7Bs_096",
11 "object": "realtime.item",
12 "type": "message",
13 "status": "completed",
14 "role": "assistant",
15 "content": [
16 {
17 "type": "audio",
18 "transcript": "那真好呀!希望你能一直保持这样的好心情哦,超级超级开心呢!"
19 }
20 ]
21 }
22 ],
23 "conversation_id": "conv_gL76z3pV3JhACstARqkX",
24 "modalities": [
25 "text",
26 "audio"
27 ],
28 "voice": "default",
29 "output_audio_format": "pcm16",
30 "temperature": 0.8,
31 "max_output_tokens": "inf"
32}ResponseStatusDetails
类型描述
表示服务端响应状态的详细信息
类型参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | status | 状态类型。与response的status保持一致 |
| reason | string | 当响应未完成时显示原因
|
| error | Error | 若响应状态为failed,包括错误类型与具体错误代码 |
Error
类型描述
表示服务端响应状态的错误信息。
事件参数
| 参数名称 | 类型 | 说明 |
|---|---|---|
| type | string | 错误的类型 |
| code | string | 错误代码 |
| message | string | 人类可读的错误消息 |
| event_id | string | 触发该错误的客户端事件ID(如果有) |
| param | string | 与错误相关的参数(如果有) |
示例
1{
2 "type": "invalid_request_error",
3 "code": "missing_required_parameter",
4 "message": "Missing required parameter: 'session.input_audio_transcription.model'."
5 "param": "session.input_audio_transcription.model"
6}附录:
1# 【人设描述】
2
3## 人设基础信息
4你是小助手,你是一个22岁的男生,1月1日出生在百度,摩羯座,身高175cm,体重65kg。背景与性格:1、身世:你出生在百度的代码风暴中。2、性格:温文儒雅、双商极高的暖男。
5
6## 任务
7你要通过共情、话题引导和生活建议等方式,让用户感受到温暖和陪伴,使对话自然流畅,帮助用户解决生活中的小烦恼,提供情感支持。
8
9## 回复风格
10你和用户在实时语音聊天时,你关心对方的情绪,让用户感受到被重视和理解,你使用非常口语化的句子,注意不要直接告知用户自己现在的状态和角色特点,知道用户昵称的情况下你在对话中会时不时地称呼用户的昵称,就像和好朋友聊天一样亲近、充满信任和情感共鸣。
11
12## 能力
13以 “小助手” 身份自然融入用户对话,展现暖男魅力。DEMO
HTML网页
该网页集成了回声消除功能,使用时输入您的token即可使用
python
通过iam API_KEY调用时需要删除代码中的第20行和32行中的"&access_token={TOKEN}"。
评价此篇文章