
快速入门
更新时间:2024-12-12
Step1:账号登录及资源领取
调用百度智能云的内容审核能力,首先需注册百度智能云账号:
点击此处注册百度账户,即可进行账号创建及登录。
完成实名认证,操作细节请参考实名认证文档。只有完成了实名认证才能购买并使用文内容审核服务。
登录百度智能云账号后,找到产品服务-人工智能下的内容审核产品。
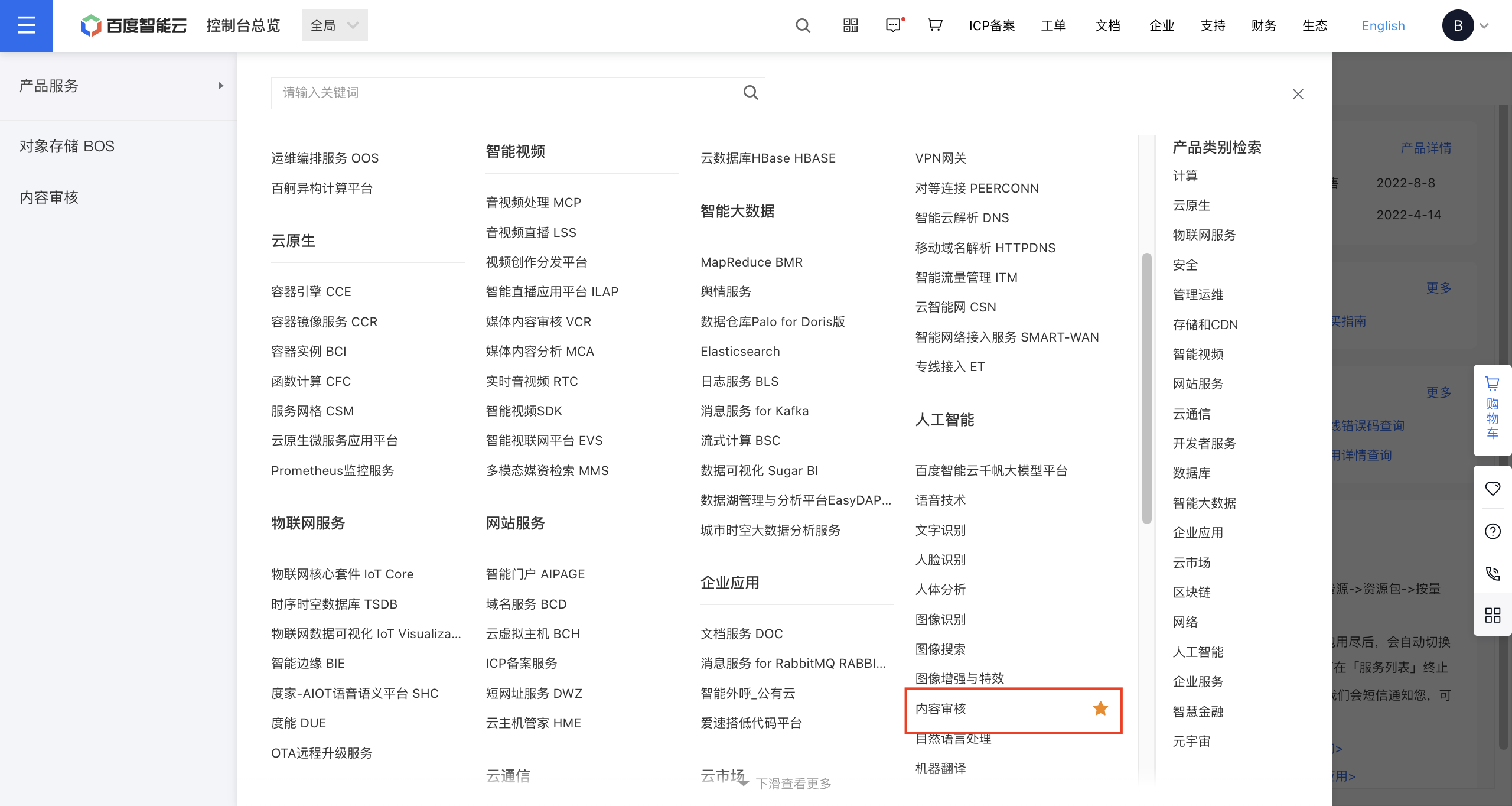
根据操作指引,分别完成实名认证、创建应用、配置策略和调用服务
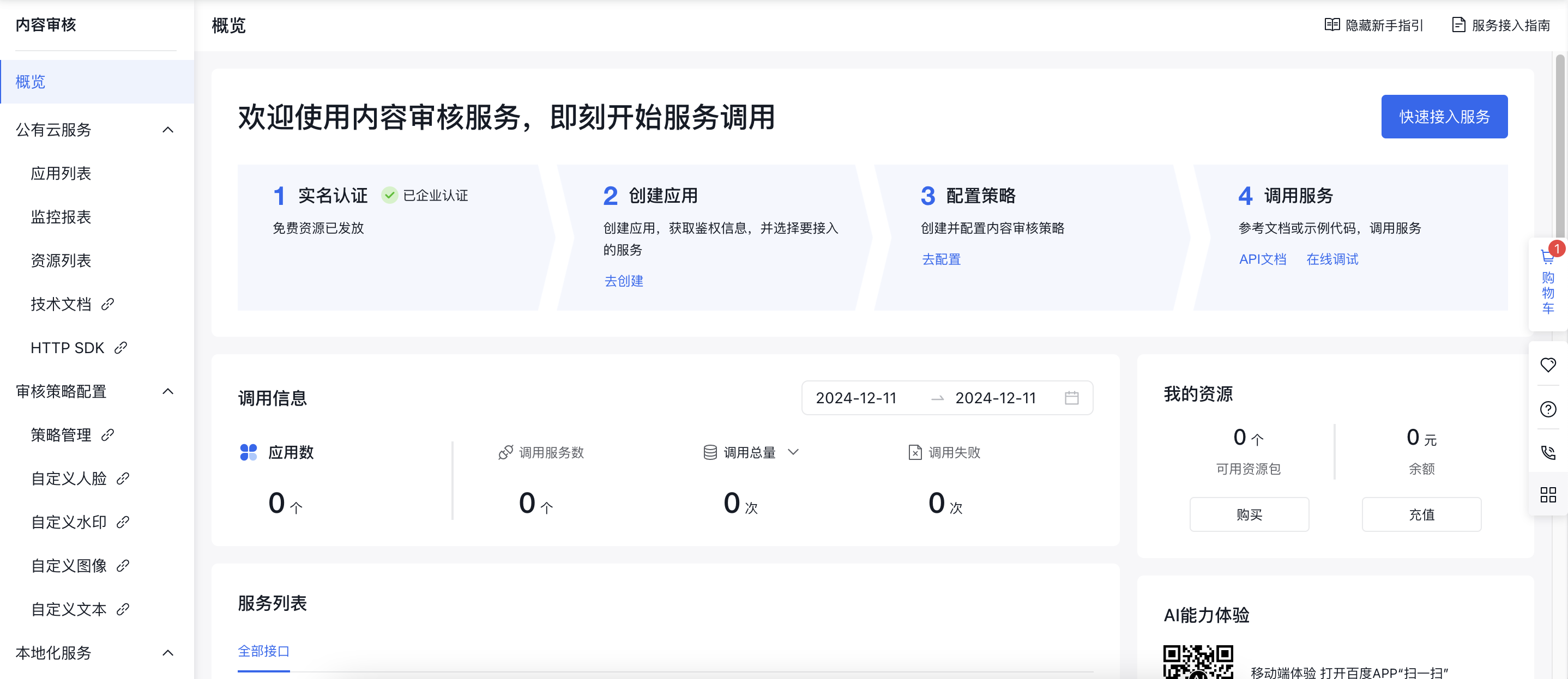
Step2:在线验证
创建应用与配置策略完成后,即可在内容审核平台进行在线验证
策略管理页面
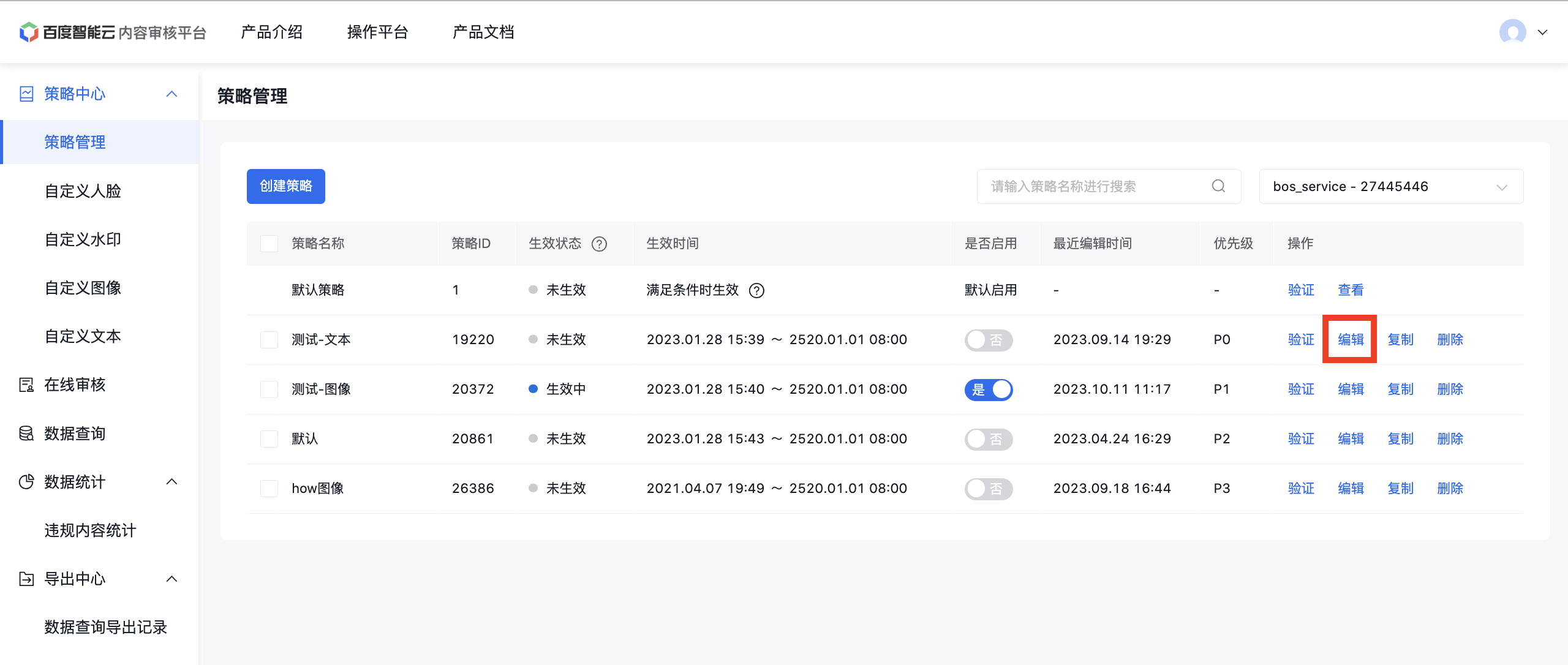
策略配置页面
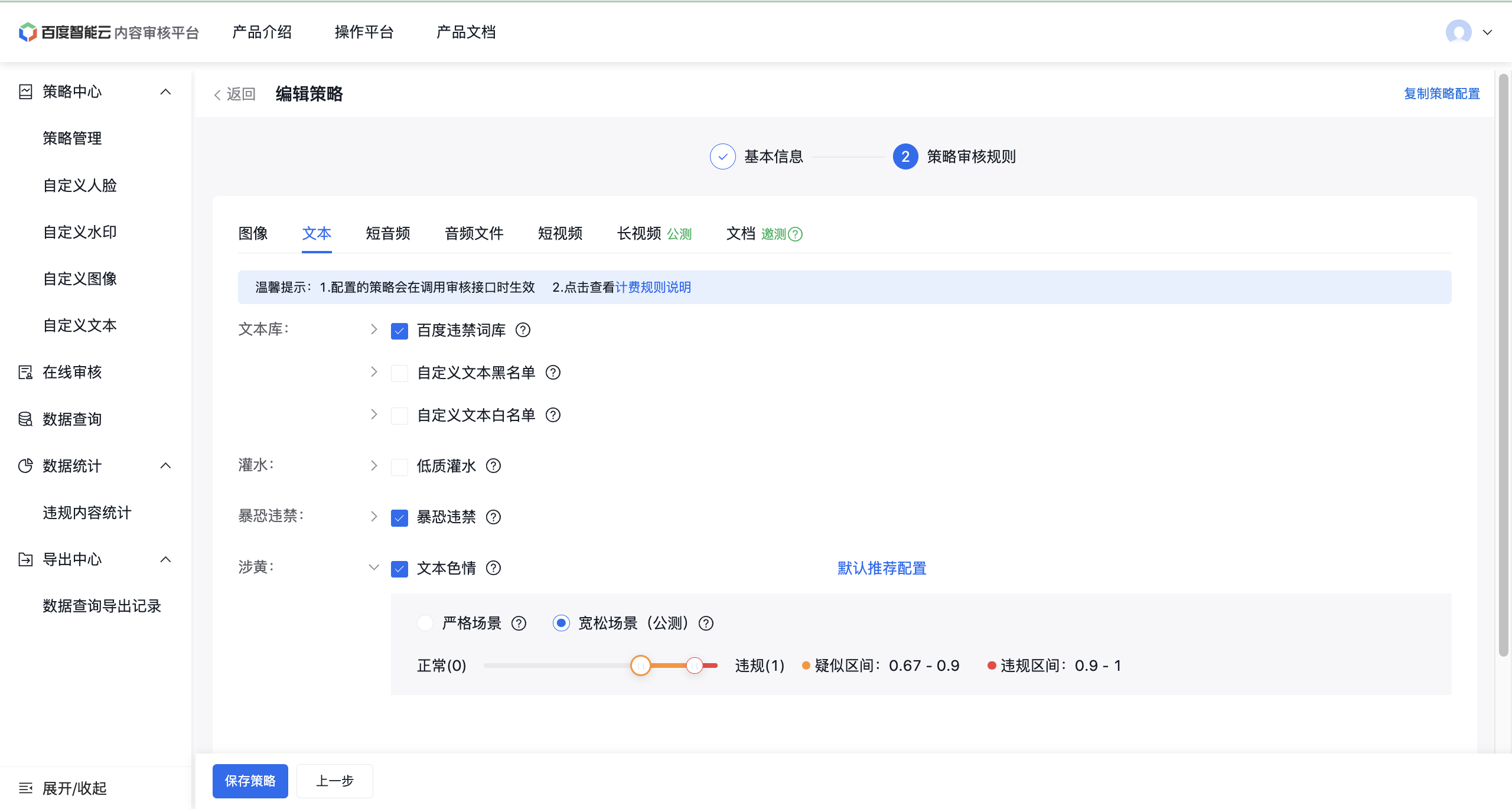
在线审核/验证页面
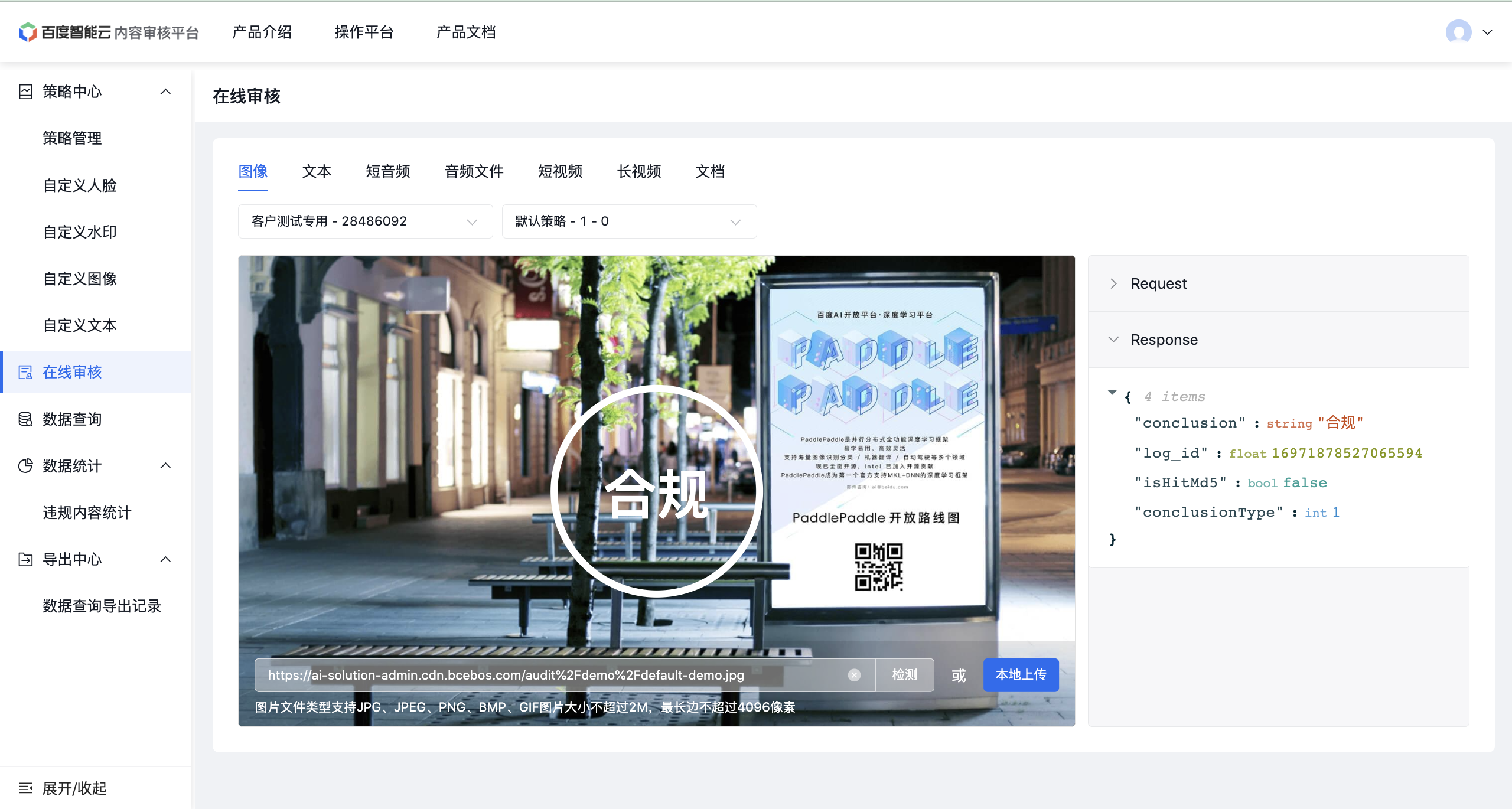
Step3: 编写示例程序
根据第一步创建应用时生成的API KEY 以及 Secret KEY,我们就可以写一个示例代码调用百度AI开放平台的内容审核能力
准备开发环境
我们选择用python来快速搭建一个原型,关于如何安装python。可以参考下表列出的不同操作系统的安装方法进行安装。
Python的官方下载地址:下载python

Windows 快速测试包
Windows平台的用户如果对上述的python安装感到困难,可以下载我们的一键测试包,下载地址:Windows测试包。
解压zip文件后,双击run.bat即可测试。
编写代码
新建一个 main.py
粘贴以下内容,不要忘记替换你的 API_KEY 以及 SECRET_KEY:
Plain Text
1# coding=utf-8
2
3import sys
4import json
5import base64
6
7
8# 保证兼容python2以及python3
9IS_PY3 = sys.version_info.major == 3
10if IS_PY3:
11 from urllib.request import urlopen
12 from urllib.request import Request
13 from urllib.error import URLError
14 from urllib.parse import urlencode
15 from urllib.parse import quote_plus
16else:
17 import urllib2
18 from urllib import quote_plus
19 from urllib2 import urlopen
20 from urllib2 import Request
21 from urllib2 import URLError
22 from urllib import urlencode
23
24# 防止https证书校验不正确
25import ssl
26ssl._create_default_https_context = ssl._create_unverified_context
27
28API_KEY = 'eQnGqPdFTTctqkjHvdUEzmrC'
29
30SECRET_KEY = 'HDBuwWT4pfSBGyLkTEAYhwoQkoDGrWU2'
31
32
33IMAGE_CENSOR = "https://aip.baidubce.com/rest/2.0/solution/v1/img_censor/v2/user_defined"
34
35TEXT_CENSOR = "https://aip.baidubce.com/rest/2.0/solution/v1/text_censor/v2/user_defined";
36
37""" TOKEN start """
38TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
39
40
41"""
42 获取token
43"""
44def fetch_token():
45 params = {'grant_type': 'client_credentials',
46 'client_id': API_KEY,
47 'client_secret': SECRET_KEY}
48 post_data = urlencode(params)
49 if (IS_PY3):
50 post_data = post_data.encode('utf-8')
51 req = Request(TOKEN_URL, post_data)
52 try:
53 f = urlopen(req, timeout=5)
54 result_str = f.read()
55 except URLError as err:
56 print(err)
57 if (IS_PY3):
58 result_str = result_str.decode()
59
60
61 result = json.loads(result_str)
62
63 if ('access_token' in result.keys() and 'scope' in result.keys()):
64 if not 'brain_all_scope' in result['scope'].split(' '):
65 print ('please ensure has check the ability')
66 exit()
67 return result['access_token']
68 else:
69 print ('please overwrite the correct API_KEY and SECRET_KEY')
70 exit()
71
72"""
73 读取文件
74"""
75def read_file(image_path):
76 f = None
77 try:
78 f = open(image_path, 'rb')
79 return f.read()
80 except:
81 print('read image file fail')
82 return None
83 finally:
84 if f:
85 f.close()
86
87
88"""
89 调用远程服务
90"""
91def request(url, data):
92 req = Request(url, data.encode('utf-8'))
93 has_error = False
94 try:
95 f = urlopen(req)
96 result_str = f.read()
97 if (IS_PY3):
98 result_str = result_str.decode()
99 return result_str
100 except URLError as err:
101 print(err)
102
103if __name__ == '__main__':
104
105 # 获取access token
106 token = fetch_token()
107
108 # 拼接图像审核url
109 image_url = IMAGE_CENSOR + "?access_token=" + token
110
111 # 拼接文本审核url
112 text_url = TEXT_CENSOR + "?access_token=" + token
113
114
115 file_content = read_file('./image_normal.jpg')
116 result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
117 print("----- 正常图调用结果 -----")
118 print(result)
119
120 file_content = read_file('./image_advertise.jpeg')
121 result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
122 print("----- 广告图调用结果 -----")
123 print(result)
124
125 text = "我们要热爱祖国热爱党"
126 result = request(text_url, urlencode({'text': text}))
127 print("----- 正常文本调用结果 -----")
128 print(result)
129
130 text = "我要爆粗口啦:百度AI真他妈好用"
131 result = request(text_url, urlencode({'text': text}))
132 print("----- 粗俗文本调用结果 -----")
133 print(result)
134 运行代码
在命令行中运行python main.py
结果
若代码正确运行,命令行界面上会显示出运行结果:
Plain Text
1 ----- 正常图调用结果 -----
2{"conclusion":"合规","log_id":15589290206915234,"conclusionType":1}
3----- 广告图调用结果 -----
4{"conclusion":"不合规","log_id":15589290221307686,"data":[{"msg":"存在水印码内容","probability":0.86516607,"type":5}],"conclusionType":2}
5----- 正常文本调用结果 -----
6{"conclusion":"合规","log_id":15589290234750607,"conclusionType":1}
7----- 粗俗文本调用结果 -----
8{"conclusion":"疑似","log_id":15589290237990632,"data":[{"msg":"疑似存在文本色情不合规","conclusion":"疑似","hits":[{"probability":0.802,"datasetName":"百度默认文本反作弊库","words":[]}],"subType":2,"conclusionType":3,"type":12}],"conclusionType":3}可以看到结果中返回了内容审核服务对于图片以及文本的审核结果,包括了概率以及不合规的类型,具体字段的含义都在内容审核技术文档中有这详细的释义。
了解更多
示例源代码
您可以在我们的官方github上下载示例源码:
https://github.com/Baidu-AIP/QuickStart/tree/master/CONTENT_CENSOR
更多参考
参见内容审核技术文档