
通过VK获取实例监控指标
除了通过百度云监控BCM查看 BCI 实例监控指标外,BCI 还支持通过 VK 查看 BCI 实例监控指标。
通过 VK 查看监控指标的方式与 Kubelet 类似,本文将分三部分介绍:
- 监控指标来源
- 支持查看的指标
- 查看指标的方式
监控指标来源
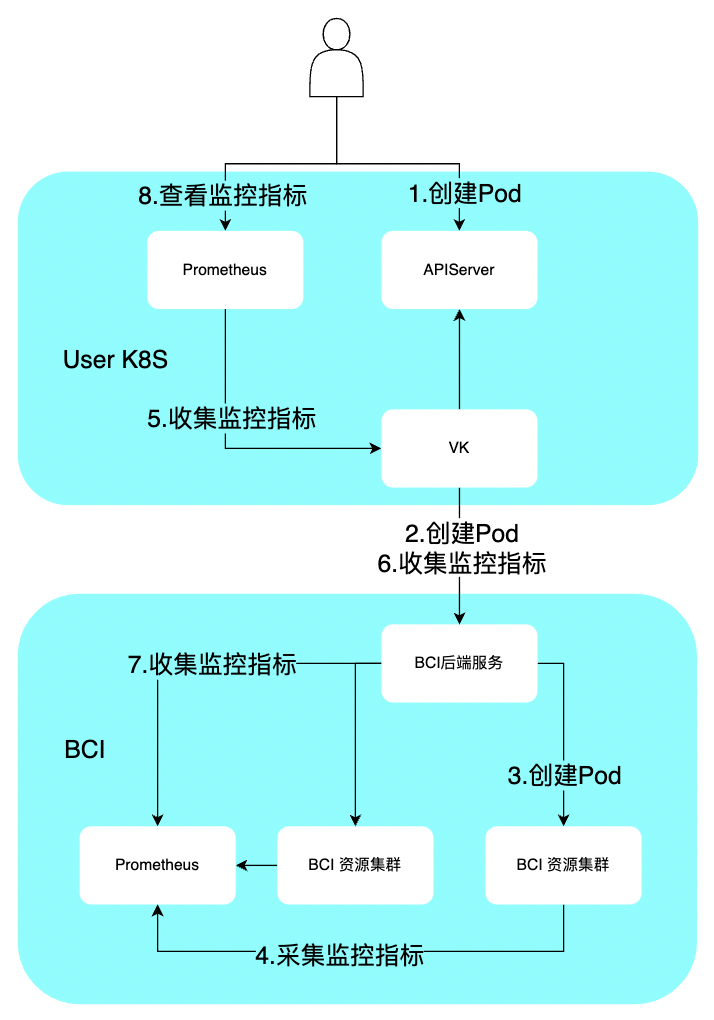
BCI实例监控指标的流向如下图所示
支持查看的指标
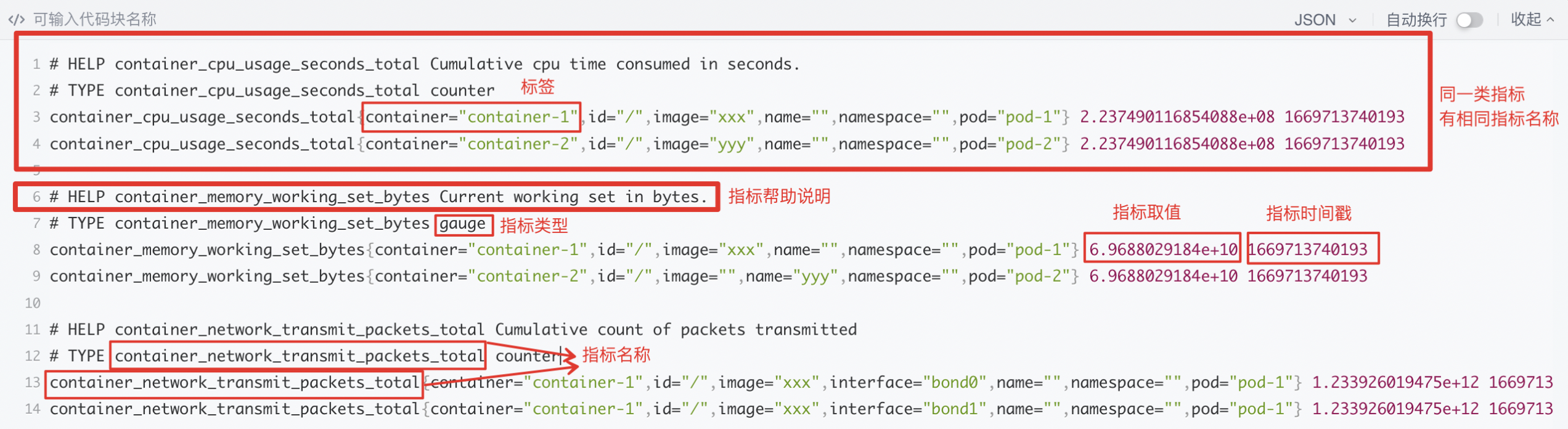
通过VK提供的监控指标是prometheus指标格式,与BCM上看到的指标有较大的差异。vk 提供的监控指标格式如下
1# 指标的帮助说明
2# 指标名称 指标类型
3指标名称{标签,标签,...} 指标取值 指标时间戳
4指标名称{标签,标签,...} 指标取值 指标时间戳
5
6# 指标的帮助说明
7# 指标名称 指标类型
8指标名称{标签,标签,...} 指标取值 指标时间戳
9指标名称{标签,标签,...} 指标取值 指标时间戳指标分为多类,每一类指标的指标名称和指标类型是都一样的,每一类指标又可分为多条(指标名称一样,标签不一样)。
每条指标都包含指标名称、标签集合、指标取值、指标时间戳四个部分。
如下图示例说明:
支持的指标:
CPU
- container_cpu_usage_seconds_total:容器创建以来,累计使用cpu的总时间(单位:秒)。
内存
- container_memory_working_set_bytes:容器正在使用的内存字节数(单位:字节)。使用的内存字节数不包含Page Cache占用的内存空间
磁盘
- container_fs_reads_bytes_total:容器创建以来,累计从文件系统读取的字节数(单位:字节)。
- container_fs_writes_bytes_total:容器创建以来,累计写入到文件系统的字节数(单位:字节)。
网络
- container_network_receive_bytes_total:容器创建以来,累计接收的网络数据字节数(单位:字节)。
- container_network_receive_packets_total:容器创建以来,累计接收的网络数据IP包数(单位:个)。
- container_network_transmit_bytes_total:容器创建以来,累计发送的网络数据字节数(单位:字节)。
- container_network_transmit_packets_total:容器创建以来,累计发送的网络数据IP包数(单位:个)。
GPU指标
目前BCI支持的GPU指标如下:
| 指标名称 | 类型 | 描述 | 示例值 |
| DCGM_FI_DEV_SM_CLOCK | gauge | # HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz). | 1695 |
| DCGM_FI_DEV_MEM_CLOCK | gauge | # HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz). | 6250 |
| DCGM_FI_DEV_GPU_TEMP | gauge | # HELP DCGM_FI_DEV_GPU_TEMP GPU temperature (in C). | 56 |
| DCGM_FI_DEV_POWER_USAGE | gauge | # HELP DCGM_FI_DEV_POWER_USAGE Power draw (in W). | 75.738000 |
| DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION | counter | # HELP DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION Total energy consumption since boot (in mJ). | 164108202242 |
| DCGM_FI_DEV_PCIE_REPLAY_COUNTER | counter | # HELP DCGM_FI_DEV_PCIE_REPLAY_COUNTER Total number of PCIe retries. | 0 |
| DCGM_FI_DEV_GPU_UTIL | gauge | # HELP DCGM_FI_DEV_GPU_UTIL GPU utilization (in %). | 0 |
| DCGM_FI_DEV_MEM_COPY_UTIL | gauge | # HELP DCGM_FI_DEV_MEM_COPY_UTIL Memory utilization (in %). | 0 |
| DCGM_FI_DEV_ENC_UTIL | gauge | # HELP DCGM_FI_DEV_ENC_UTIL Encoder utilization (in %). | 0 |
| DCGM_FI_DEV_DEC_UTIL | gauge | # HELP DCGM_FI_DEV_DEC_UTIL Decoder utilization (in %). | 0 |
| DCGM_FI_DEV_XID_ERRORS | gauge | # HELP DCGM_FI_DEV_XID_ERRORS Value of the last XID error encountered. | 0 |
| DCGM_FI_DEV_FB_FREE | gauge | # HELP DCGM_FI_DEV_FB_FREE Framebuffer memory free (in MiB). | 5774 |
| DCGM_FI_DEV_FB_USED | gauge | # HELP DCGM_FI_DEV_FB_USED Framebuffer memory used (in MiB). | 16957 |
| DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL | counter | # HELP DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL Total number of NVLink bandwidth counters for all lanes | 0 |
| DCGM_FI_DEV_VGPU_LICENSE_STATUS | gauge | # HELP DCGM_FI_DEV_VGPU_LICENSE_STATUS vGPU License status | 0 |
| DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS | counter | # HELP DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS Number of remapped rows for uncorrectable errors | 0 |
| DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS | counter | # HELP DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS Number of remapped rows for correctable errors | 0 |
| DCGM_FI_DEV_ROW_REMAP_FAILURE | gauge | # HELP DCGM_FI_DEV_ROW_REMAP_FAILURE Whether remapping of rows has failed | 0 |
| DCGM_FI_PROF_PIPE_TENSOR_ACTIVE | gauge | # HELP DCGM_FI_PROF_PIPE_TENSOR_ACTIVE Ratio of cycles the tensor (HMMA) pipe is active (in %). | 0.037385 |
| DCGM_FI_PROF_GR_ENGINE_ACTIVE | gauge | # HELP DCGM_FI_PROF_GR_ENGINE_ACTIVE Ratio of time the graphics engine is active (in %). | 0.130759 |
| DCGM_FI_PROF_SM_ACTIVE | gauge | # HELP DCGM_FI_PROF_SM_ACTIVE The ratio of cycles an SM has at least 1 warp assigned (in %). | 0.110320 |
| DCGM_FI_PROF_SM_OCCUPANCY | gauge | # HELP DCGM_FI_PROF_SM_OCCUPANCY The ratio of number of warps resident on an SM (in %). | 0.045643 |
| DCGM_FI_PROF_DRAM_ACTIVE | gauge | # HELP DCGM_FI_PROF_DRAM_ACTIVE Ratio of cycles the device memory interface is active sending or receiving data (in %). | 0.065867 |
| DCGM_FI_PROF_PCIE_TX_BYTES | counter | # HELP DCGM_FI_PROF_PCIE_TX_BYTES The number of bytes of active pcie tx data including both header and payload. | 64522980 |
| DCGM_FI_PROF_PCIE_RX_BYTES | counter | # HELP DCGM_FI_PROF_PCIE_RX_BYTES The number of bytes of active pcie rx data including both header and payload. | 8436715 |
如您使用CCE的prometheus 监控,在VK的cadvisor接口访问获取指标,需要将CCE原始的cadvisor指标采集任务关闭,因为原始的cadvisor指标只采集的免费的指标;
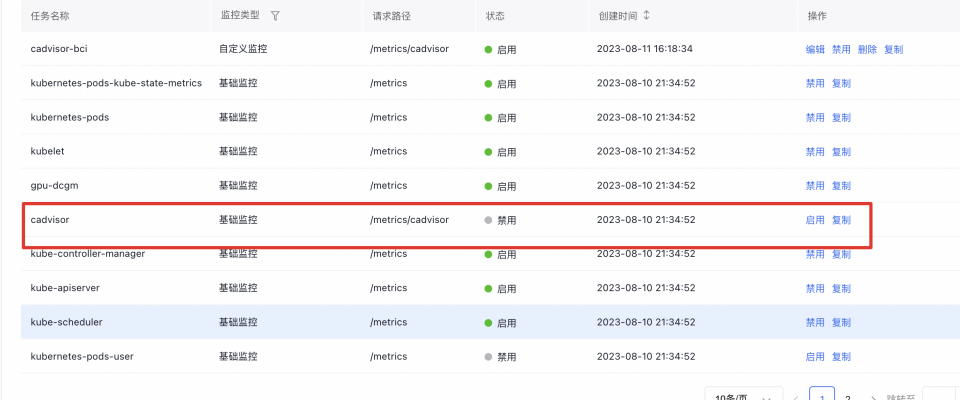
将cadvisor指标拷贝一份,添加想要采集的DCGM指标,配置如下:
1job_name: 'cadvisor-gpu'
2scheme: https
3tls_config:
4 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
5 insecure_skip_verify: true
6bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
7metrics_path: /metrics/cadvisor
8kubernetes_sd_configs:
9 - role: node
10relabel_configs:
11 - action: labelmap
12 regex: __meta_kubernetes_node_label_(.+)
13 - source_labels: [ instance ]
14 action: replace
15 target_label: node
16metric_relabel_configs:
17 - source_labels: [__name__]
18 action: keep
19 regex: (machine_(cpu_cores|memory_bytes)|container_(cpu_usage_seconds_total|fs_limit_bytes|fs_reads_bytes_total|
20 fs_usage_bytes|fs_writes_bytes_total|memory_working_set_bytes|network_receive_bytes_total|
21 network_receive_packets_dropped_total|network_receive_packets_total|network_transmit_bytes_total|
22 network_transmit_packets_dropped_total|network_transmit_packets_total)|DCGM_(FI_DEV_GPU_UTIL|FI_DEV_GPU_TEMP|FI_DEV_FB_USED|FI_DEV_FB_FREE|FI_DEV_POWER_USAGE|FI_PROF_SM_ACTIVE|FI_PROF_PCIE_RX_BYTES|FI_PROF_PCIE_TX_BYTES))支持的标签:
- container:容器名称
- id:容器复杂ID
- image:容器镜像地址
- name:容器简单ID
- namespace:Pod所在的名字空间
- pod:容器所在的Pod
- device:指标所属的块设备,此标签只在 container_fs_xxx 等几个指标中存在
- interface:指标所属的网卡设备,此标签只在 container_network_xxx 等几个指标中存在
注意:使用了镜像加速功能的容器,其监控指标中的 image 并非用户原始镜像,而是 {ACCELERATE_PREFIX}/transfer/{ACCOUNT_ID}/{USER_ORIGINAL_IMAGE}_accelerate {ACCELERATE_PREFIX} 镜像加速添加的前缀 {ACCOUNT_ID} 用户的账户ID {USER_ORIGINAL_IMAGE} 用户原始镜像地址
查看指标的方式
通过 VK 查看 BCI 监控指标
通过 VK 查看 BCI 监控指标的方式,与通过 Kubelet 查看 cAdvisor 指标的方式一样,通过如下接口查看
1Host: {KubeletServer}
2Port: 10250
3URI: GET /metrics/cadvisor
4Param:无通过 vk 查看BCI实例监控指标,示例如下
1./kubectl --kubeconfig={kubeconfig_path} get --raw "/api/v1/nodes/{vk_bci_kubelet_name}/proxy/metrics/cadvisor"
2// {vk_bci_kubelet_name} vk 的 nodeName通过 Prometheus 采集并查看 BCI 监控指标
通过 Prometheus 采集存储 BCI实例监控指标,简单配置(prometheus.yml)如下
1global:
2 scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
3 evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
4 # scrape_timeout is set to the global default (10s).
5
6# Alertmanager configuration
7alerting:
8 alertmanagers:
9 - static_configs:
10 - targets:
11 # - alertmanager:9093
12
13# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
14rule_files:
15 # - "first_rules.yml"
16 # - "second_rules.yml"
17
18# A scrape configuration containing exactly one endpoint to scrape:
19# Here it's Prometheus itself.
20scrape_configs:
21 # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
22 - job_name: "prometheus"
23 static_configs:
24 - targets: ["localhost:9090"]
25 - job_name: "cadvisor"
26 static_configs:
27 - targets: ['47.92.228.38:10250'] // 此处 47.92.228.38 是 vk 因特网可访问的 ip,10250 是 vk 的 https server 端口(注意不是 http)
28 scheme: https
29 metrics_path: /metrics/cadvisor
30 tls_config:
31 insecure_skip_verify: true // 作为一个demo示例,关闭 tls 协议
32 authorization:
33 credentials_file: /home/work/prometheus/token // 可以正常访问 node server 的 bearer token
34 relabel_configs:
35 - action: labelmap
36 regex: __meta_kubernetes_node_label_(.+)- targets:vk 的 ip:port,注意该 ip 是需要能够被 prometheus 访问的,port 是 kubelet 对外暴露 /metrics/cadvisor 接口的端口(一般是10250)
- credentials_file:有访问 node 权限的 service account 的 token;
启动命令
1./prometheus --config.file="prometheus.yml"评价此篇文章